微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
最近我们团队[1]在vLLM上开发了一种KV cache传输的connector,实现了传输性能0.5x的提升[2],相关代码已全部开源。在过程中遇到的挑战/问题在这里进行一个分享,希望能给从事相关行业的读者带来些思考与借鉴。
基础知识参看上一篇:
从原理到演进:vLLM PD分离KV cache传递机制全解析
1 问题模型分析
总体需求:LLM的推理PD分离场景下,Prefill实例要将计算好的KV cache传输给Decode实例进行后续运算,需要设计一种高效的传输机制保证推理性能。
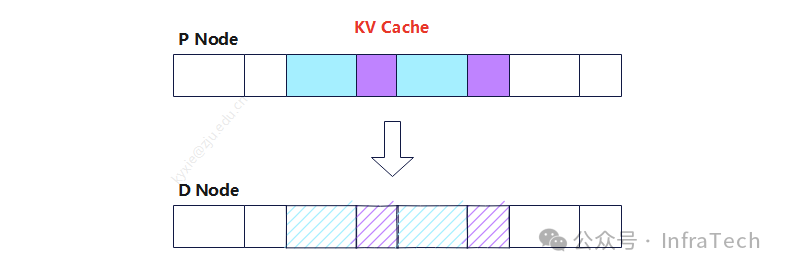
添加图片注释,不超过 140 字(可选)
由于变量因素较多需要降低讨论问题模型复杂度,限定:
-
模型类型为LLM(deepseek/qwen等);
-
推理框架为vLLM V1版本;
-
传输通道使用P2P GPU<->GPU。
1.1 数据
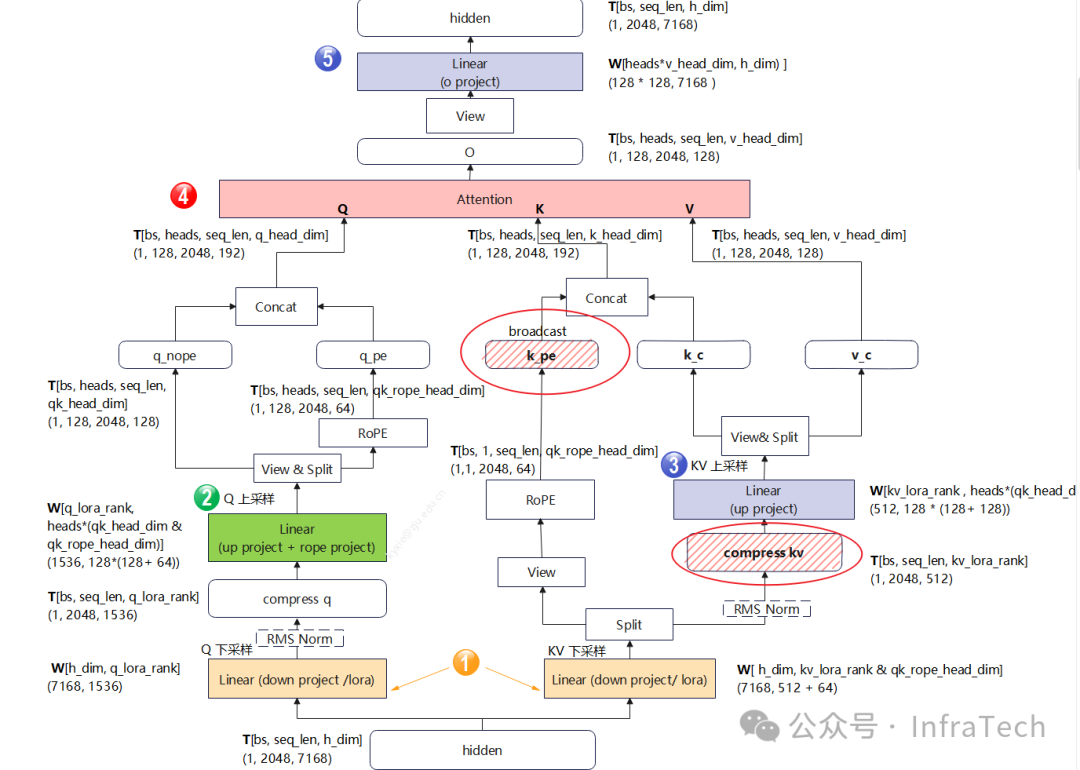
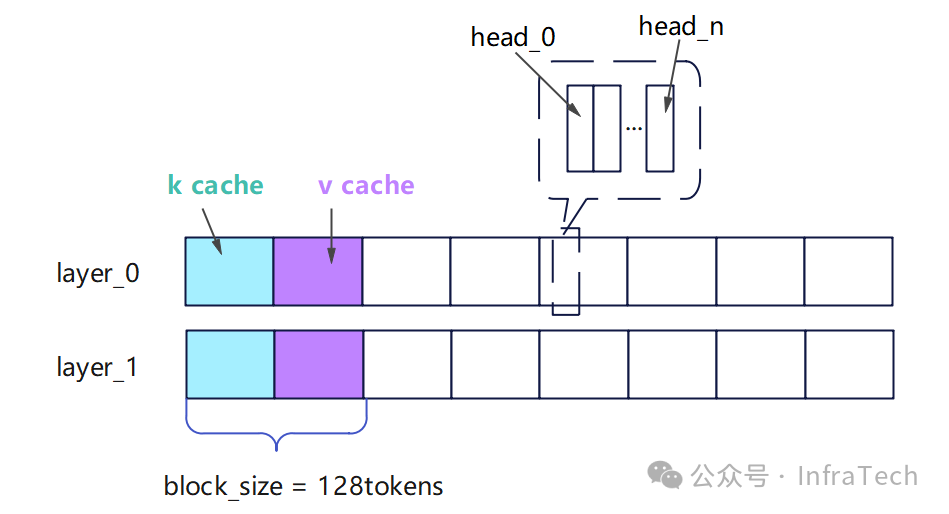
KV cache数据在MLA和GQA/MHA中存储的形态略有不同。先看MLA结构中KV cache存储形态,下图中需要存储的cache是k_pe(rope)和compress_kv(nope),其数据的大小:
kv_cache_size = total_seq_len x (kv_lora_rank + qk_rope_head_dim) x dtype
添加图片注释,不超过 140 字(可选)
vLLM的cache管理分为逻辑层和物理层(参考文末资料1),对于传输而言仅需要感知物理层的数据,要解答该问题先找到对应物理层cache管理的代码位置,了解其现状。
KV cache的创建:在GPU runner中有一个_allocate_kv_cache_tensors函数,通过torch.tensor逐层创建kv_cache_tensor,也就是说模型每层共用一个tensor数据。
# 代码位置:vllm/v1/worker/gpu_model_runner.py
接下来了解不同请求是如何使用这个kv_cache_tensor的。在kv_cache_utils中找到blocks的划分逻辑,定义了blocks的数量计算方式为:可用显存/单页尺寸/层数。
# 代码位置:vllm/vllm/v1/core/kv_cache_utils.py
接着在kv_cache_interface中找到page_size的计算方式,如下所示,其中关键参数block_size大小一般设置为128.
# 代码位置:vllm/v1/kv_cache_interface.py
综合以上信息,MLA的KV cache在内存中的一种形态如下图所示,其nope与rope相邻(另一种后面介绍)。

添加图片注释,不超过 140 字(可选)
KV cache的大小计算:kv_lora_rank为64,qk_rope_head_dim为128,采用半精度存储,这样可以算得每个block的数据量为144K。
其中nope块的大小是:128 * 512 * 2 / 1024 = 128k
rope块的大小是: 128 * 64 * 2 / 1024 = 16K
GQA/MHA的KV cache形态与MLA的有所不同,GQA的cache是未经过投影压缩的全量值,同条件下数据量更大,且存储时K值和V值大小相等,所以page_size计算时的cof系数取2。
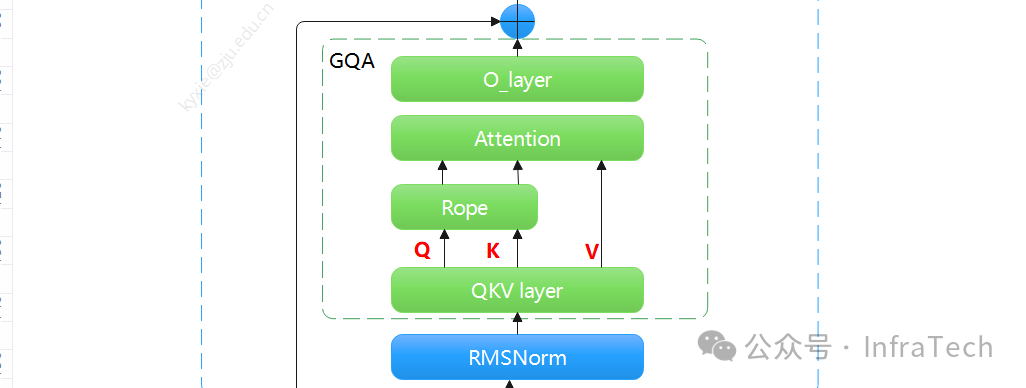
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
存储的blocks数据在attention算子完成计算中更新,然后进入传输环节。
算子可以用flashattention,输入的KV cache数据会先映射到一个多维矩阵上面,然后传入kernel中计算。只有当P节点完成attention计算,KV cache才允许传输。
# 代码位置:vllm/vllm/v1/attention/backends/flash_attn.py
MLA、GQA还有另一种存储形态,就是将数据按照类型进行分段存储,如下图所示。这种数据形态能够提升运算时的效率,但传输时需要多一步操作。

添加图片注释,不超过 140 字(可选)
1.2 设计条件
了解完数据形态,接下来看一下我们的设计条件(设计约束)。
通道:KV cache的传输方式采用RDMA/HCCS,实现过程要借助已有的通信库HCCL/TCP。
链路:当前会遇到P与D异构部署场景,即P的KV cache 与D的 KV cache不能用一一对应,会出现传输时多对一的建链拓扑。同时传输链路可能是经过了多层交换机转发的路线:

添加图片注释,不超过 140 字(可选)
传输参数:传输数据总量和理论传输时间可以进行粗略评估,以dsv3为例,单次请求传输的计算公式:
total_data = (kv_lora_rank+qk_rope_head_dim) x dtype x length
elapsed_time = total_data / (bw * cof)
假设RoCE通道的带宽bw为100 Gbps (Gigabits per second),传输效率系数cof为90%,则可估算出不同序列长度的传输时间:
单次的传输耗时跟序列长度正相关,传输时间太长会影响首token或次token的生成时间,即TTFT、TPOT指标。数据碎片化(blocks存储,单位是128K/16K或者144K )会降低cof,影响传输时间。
上层框架:在vLLM V1版本中,PD分离传输需要适配connector。有一个模板基类KVConnectorBase_V1(位置vllm/distributed/kv_transfer/kv_connector/v1/base.py),这个模块涉及多个部分的实现:
-
scheduler connector的接口;
-
worker connector接口;
-
底层传输transfer layer接口;
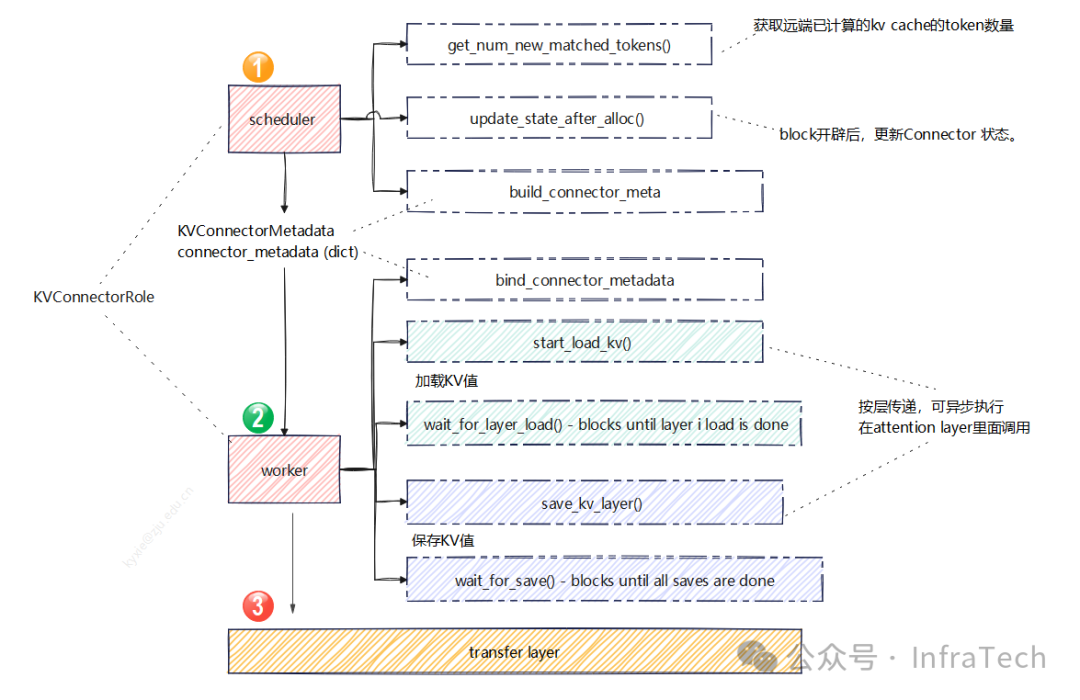
添加图片注释,不超过 140 字(可选)
2 方案实施
-
目标:在Ascend 910B机器上,采用RDMA方式完成KV Cache在NPU上的D2D传输。
-
功能:vLLM上实现一个适合Ascend芯片的connector;Mooncake上实现一版适配Ascend的TE(Transfer Engine)。
-
收益:高带宽利用率、低时延、无重复显存开销。
2.1 TransferEngine的适配
第一步要将Ascend Transport整合到Mooncake的TE(TransferEngine)中,让TE具备npu tensor的P2P传输能力。在Mooncake github仓里面能够找到TE的定义位置:TE对外提供一套API接口,兼容了多种传输方式nvlink、RDMA、TCP等,其关键函数列举:
// 代码源文件:https://github.com/kvcache-ai/Mooncake/blob/main/mooncake-transfer-engine/src
函数功能包括:建立链路、注册内存、提交传递任务、查询传递状态、解除注册、释放资源等。NPU设备的接入需按照相同逻辑实现这些接口功能。

添加图片注释,不超过 140 字(可选)
-
init:建立起设备之间辅助链路,传递元信息(如对端设备IP、端口等);
-
registerLocalMemory:申请的KV cache后,将其注册到TE中;
-
submitTransfer:下发传递任务,触发目标数据传输;
-
getTransferStatus:查询传递状态。
详细代码参考PR:https://github.com/kvcache-ai/Mooncake/pull/502
2.2 connector的适配
在vLLM中KV connector有个基类的定义,已实现的子类有lmcache_connector、 nixl_connector。
# 基类位置:vllm/vllm/distributed/kv_transfer/kv_connector/v1/base.py
参考这些内容,实现一个基于mooncake的connector,涉及的关键类有:
-
MooncakeConnectorScheduler:调度器使用的接口
-
MooncakeConnectorWorker:worker使用的接口
-
MooncakeConnectorWorker:符合TE传递的元数据
最后整合成一个新的子类:MooncakeConnector。
class MooncakeConnector(KVConnectorBase_V1)
代码参考PR:https://github.com/vllm-project/vllm-ascend/pull/1568
整个代码实现过程中遇到了一些关键挑战和问题,接下来挑几个重点讲解。
2.3 关键挑战: MLA异构传输
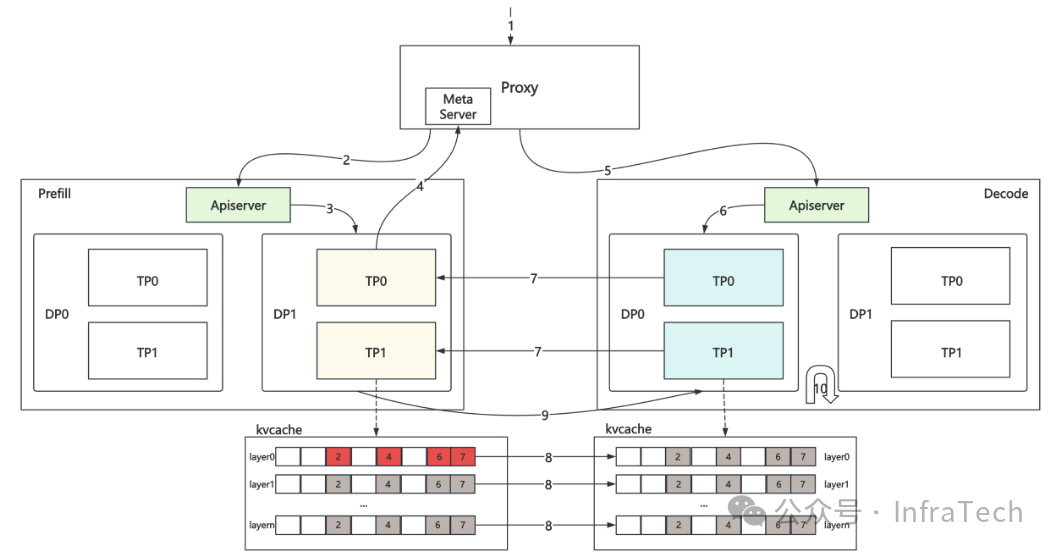
在MLA中多TP场景下,KV cache存在冗余存储,默认情况下会出现D的不同rank从同一个P的rank拉取kv cache的问题。举个例子,在单请求数据处理时,Prefill的1个DP域有2个rank,每个rank有相同的KV cache;Decode的1个DP域有4个rank,出现了4对1的数据拉取情况,如下图所示。
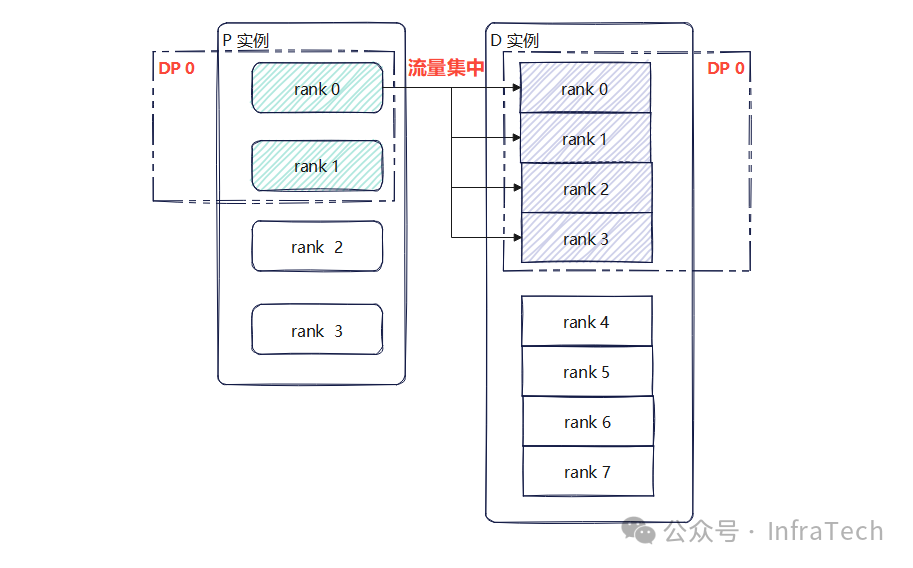
添加图片注释,不超过 140 字(可选)
代码在PR中的位置
2.4 关键挑战: GQA异构传输
GQA传输中,若开启了TP切分(不同的head存储在不同rank上),且P实例与D实例的切分策略不一样,则要考虑数据如何切分或者还原。这里举一个例子:假设heads是2,tokens为2,传递数据的两个实例中的一个实例的每个rank保存1个head(TP=2),另一个实例的rank有2个heads(TP=1)。
场景一:实例1是Prefill、实例2是Decode。由于传输按照Blocks为单位,tokens传递完成后数据未对齐,heads不一致,需要进行数据的转换操作。
场景二:实例2是Prefill、实例1是Decode,传输的数据需要进行切分操作。

添加图片注释,不超过 140 字(可选)
转换/切分操作可以是传输前或者传输后完成,两个方案对应了两种优化手段,目前我们采用的是先传输后转换。2.5 关键问题: 内存对齐
实践中发现待传输数据地址必须2M对齐,这个问题是HCCL传输的一个限制。更具体一点就是在KV cache传输的过程中首地址必须是2M的倍数:data_address_ptr % 2M = 0,而采用torch.tensor创建的显存地址一般不满足这个条件,所以需要对齐地址。
解决方案:申请前补齐一个2M的size,然后再进行torch.tensor创建,接着进行首、尾地址对齐。
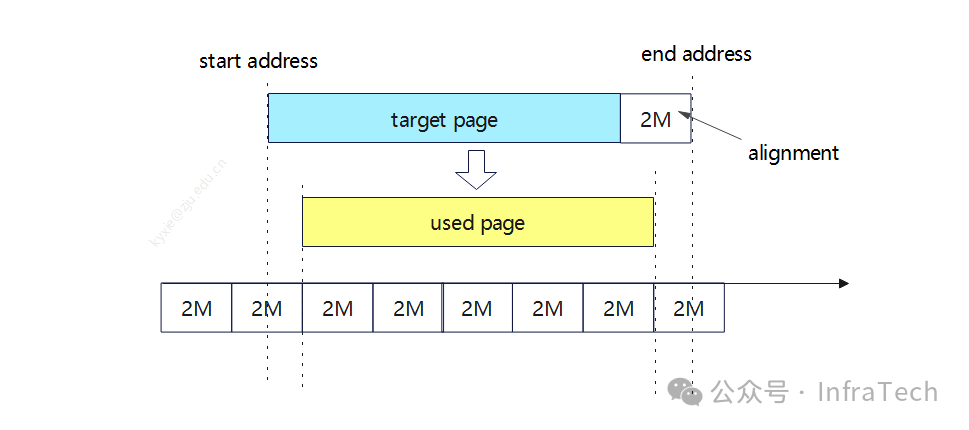
添加图片注释,不超过 140 字(可选)
# 代码位置:https://github.com/vllm-project/vllm-ascend/blob/main/vllm_ascend/worker/model_runner_v1.py#L2254
2.6 关键挑战:传输合并
在paged attention中的block数据可能出现不连续的现象,这样传输一个请求的KV cache时会出现大量的小包传输,从而导致带宽利用率低。
解决方案:当数据小于阈值时,进行数据凑整,用一个buffer进行数据打包聚合再传输;当数据包大于阈值时直接传输(下图中方式2)。进一步,为了降低小包传输前的聚合操作对性能的影响,可以开启双流工作:一条流进行数据拷贝、一条流进行数据传输(下图中方式1)。

添加图片注释,不超过 140 字(可选)
2.7 关键问题:聚合的调整
在vLLM已合入的一个PR(pull/19555)中对PD传输代码基类进行了修改,其调整了传输结束的标记信号的聚合逻辑,结束信号由work0处聚合改到了由MultiprocExecutor进行聚合:
This PR makes the following changes: Change MultiprocExecutor to get ModelRunnerOutput from all workers, and aggregate the finished_sending and finished_recving from all. Remove the worker aggregation of those fields in NixlConnector.
导致已合入的connector代码需要进行修改才能正常跑通。同时还存在一个问题就是kv_output_aggregator进行聚合运算中,判断当前请求是否能释放KV cache的计数标记选用的是world_size,这不满足一些常见场景下的传输需求。例如在MLA中KV cache是冗余的,假设Decode实例的TP小于Prefill实例的TP,如下所示P有4个rank、D有2个rank,传输的计数2次即可,但P节点world_size=4,计数永远达不到4次,导致系统因一直无法完成传输而出现故障。
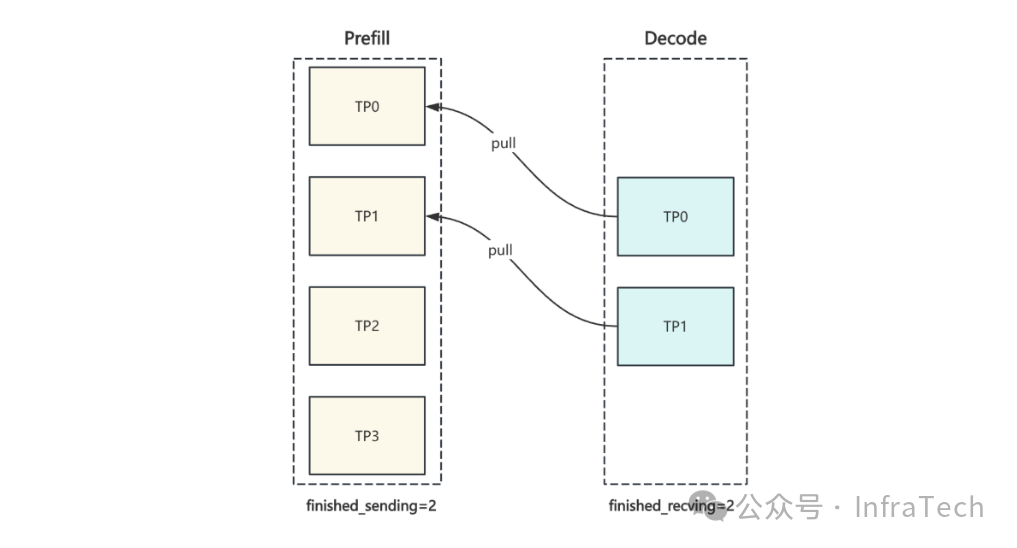
添加图片注释,不超过 140 字(可选)
-
hyh[4]:https://github.com/vllm-project/vllm-ascend/pull/2664
-
LCAIZJ[5]:https://github.com/vllm-project/vllm/pull/23917
-
https://github.com/vllm-project/vllm/pull/19555
3 下一步工作讨论
3.1 数据结构调整
当前KV cache数据的放置方案中nope与rope是分开的,如下图所示,在传递时会增加数据拷贝的次数,相比合并放置传输时每一层会多一倍的数据拷贝操作。

添加图片注释,不超过 140 字(可选)
以DSV3模型为例,一个2K的数据会多约950次传递/拷贝操作(最差情况),下一步要考虑如何降低这些数据的copy操作。
3.2 内存对齐的优化
KV cache的内存对齐操作align_memory函数会导致内存浪费。以DeepSeekV3为例,极端情况下可能浪费的显存大小为2 x 61 x 2 = 244M,这需要考虑如何优化。
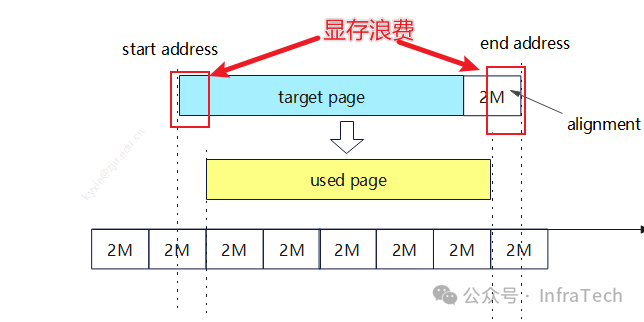
添加图片注释,不超过 140 字(可选)
3.3 分层传输功能
当单个请求的序列比较长时,若等待P实例所有层全部计算完成后再进行KV传输,会影响推理的输出性能。我们测试了DeepSeekV3/R1模型的数据传递时延如下表所示。相比MLA,GQA/MHA的传输数量更大,其时延也更大,更加需要考虑优化。

添加图片注释,不超过 140 字(可选)
这里和zzy、LCAIZJ讨论了一种按层传输(Layer-wise Strategy)的实现方式,让PD之间直接触发按层的KV cache传输,即在P计算过程中每计算完一层就立刻去向对端发送数据。
添加图片注释,不超过 140 字(可选)
方案在社区的RFC:https://github.com/vllm-project/vllm-ascend/issues/2470
3.4 GQA的异构传输优化
在2.3.2中提到了GQA异构传输,其中有个点:数据在P和D上面排布结构不相同,产生的问题需要额外的数据转换,转换与传输的操作顺序可以是:先传后转、先转后传、边转边传。其中边转边传是指传输过程中完成了数据的转置/切分操作。
优化思路:对于先传后转、先转后传的场景,考虑用双流掩盖,即起一个stream负责传递、另一个stream负责转换,每传完一层就触发转换操作,双流交替执行。
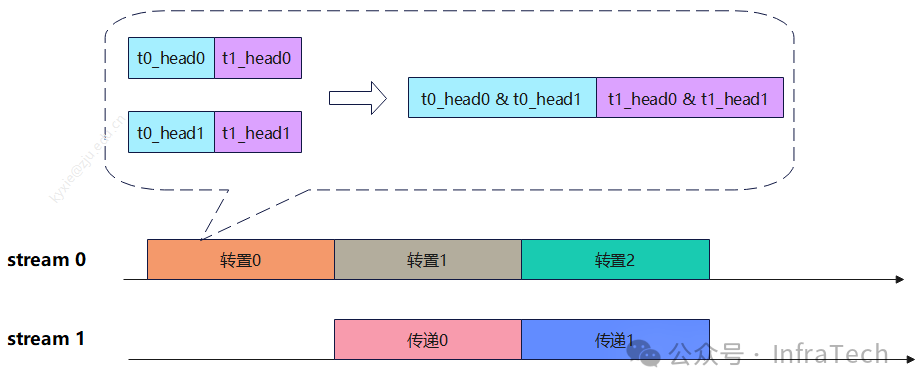
添加图片注释,不超过 140 字(可选)
对于边转边传的情况,考虑用一些定制操作(如all-to-all)。
3.5 性能提升
性能优化进行到一定程度时,KV cache传输的性能指标和一些其它指标之间会出现优化冲突,并不是仅让传输越快越好,要考虑实际的业务场景。比如(请求数少+序列长)与(请求数多+序列短)的优化的侧重点就不一样,性能优化需要平衡这些需求冲突。
-
内存开销的冲突。我们一开始的方案要求不占用额外显存,实现零内存开销拷贝,但实践中小包传输的优化要开buffer显存、内存对齐功能需占用额外显存;后续异构TP的数据转置优化可能也要占用显存。
-
易用性与可维性的冲突。在KV cache有冗余的场景中,当前采用的是直接建立点对点传输的方案,假设P与D的传输跨多层交换机则会触发流量冲突问题。下一步优化考虑让一些数据通过机内广播,从而降低机间传输的数据量。
当前性能优化场景仅考虑单xPxD的实例,下一步可尝试多xPxD的性能优化。
3.6 传输时延的归属
在PD分离的分析中聊过首token的生成问题,PD分离方案相比PD混合部署会多了一个KV cache的传输时间,如果不能被计算掩盖,那么就会影响推理的性能指标。
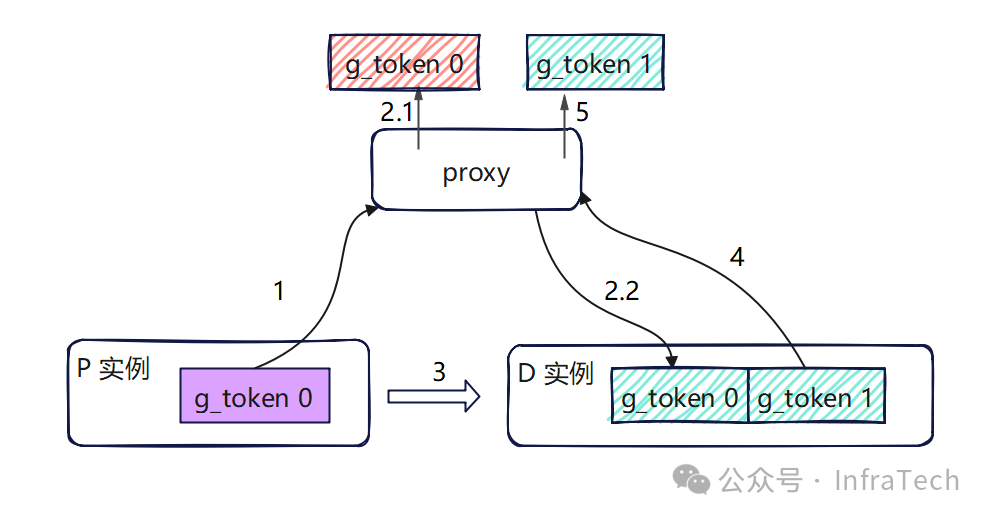
添加图片注释,不超过 140 字(可选)
-
1、P生成首token传递给proxy;
-
2、proxy将信息给D节点;
-
3、拉取KV值;
-
4、生成后续token;
-
5、输出第二个及以后的tokens。
不同场景下TTFT和TPOT的要求不一样,可以控制传输时延的归属来控制这两个指标的大小,即控制2.1步骤中首token的输出时间,调整了TTFT和TPOT的大小。后续优化中也可尝试直传hidden status/logits给D节点,让首token的生成转移到Decode操作中,如下图所示。
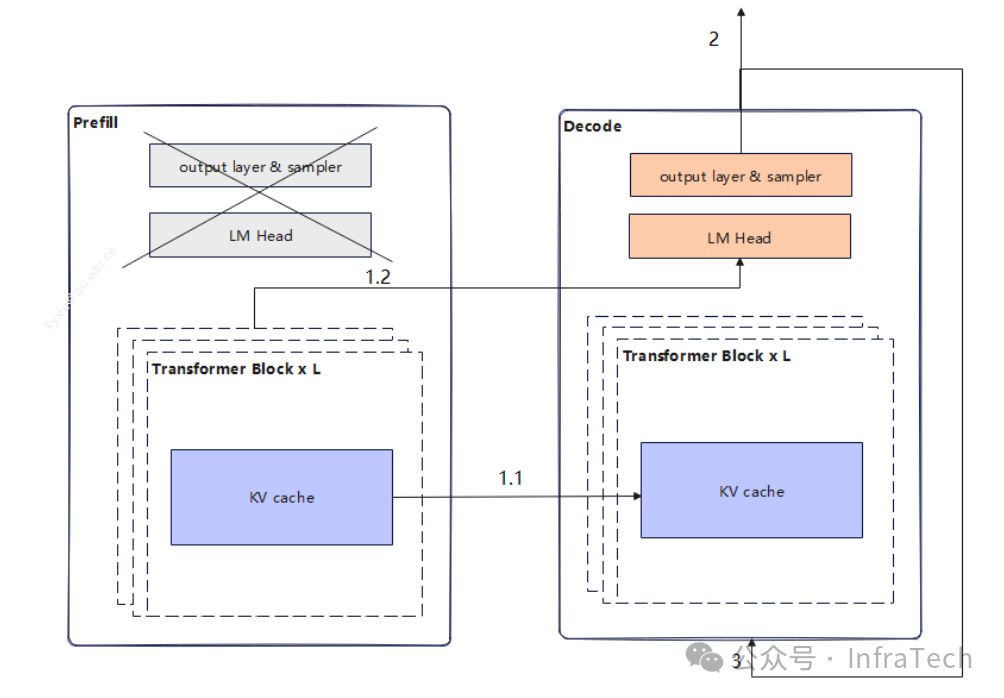
添加图片注释,不超过 140 字(可选)
-
步骤1.1: KV cache计算完成后可用layer wise传输数据,或者也可以等所有kv cache计算完成后传输数据;
-
步骤1.2 :P的最后一层完成计算后传递hidden status给D实例;
-
步骤2 :D实例进行首token计算;
-
步骤3: 等待KVcache传输完成后,decode进行后续tokens的生成。
步骤1.1和步骤1.2/2可以并发执行。
这个方案在社区提了个RFC: https://github.com/vllm-project/vllm/issues/24309
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
参考文献链接
https://mp.weixin.qq.com/s/s-UapW7XsO8RmH7mmqSDaw
[1]:PD分离传输优化HW/YN联合团队:ky、zzy、LCAIZJ、hyh等
[2]:性能参考基线为起始版本,平均提升基线为0.5x,某些情况下可能会有一定损失
[3]: zzy:https://www.zhihu.com/people/zzy-33-26
[4]: hyh:https://github.com/baxingpiaochong
[5]: LCAIZJ:https://github.com/LCAIZJ