实用指南:40.应用层协议HTTP(三)
重谈状态码(重定向)
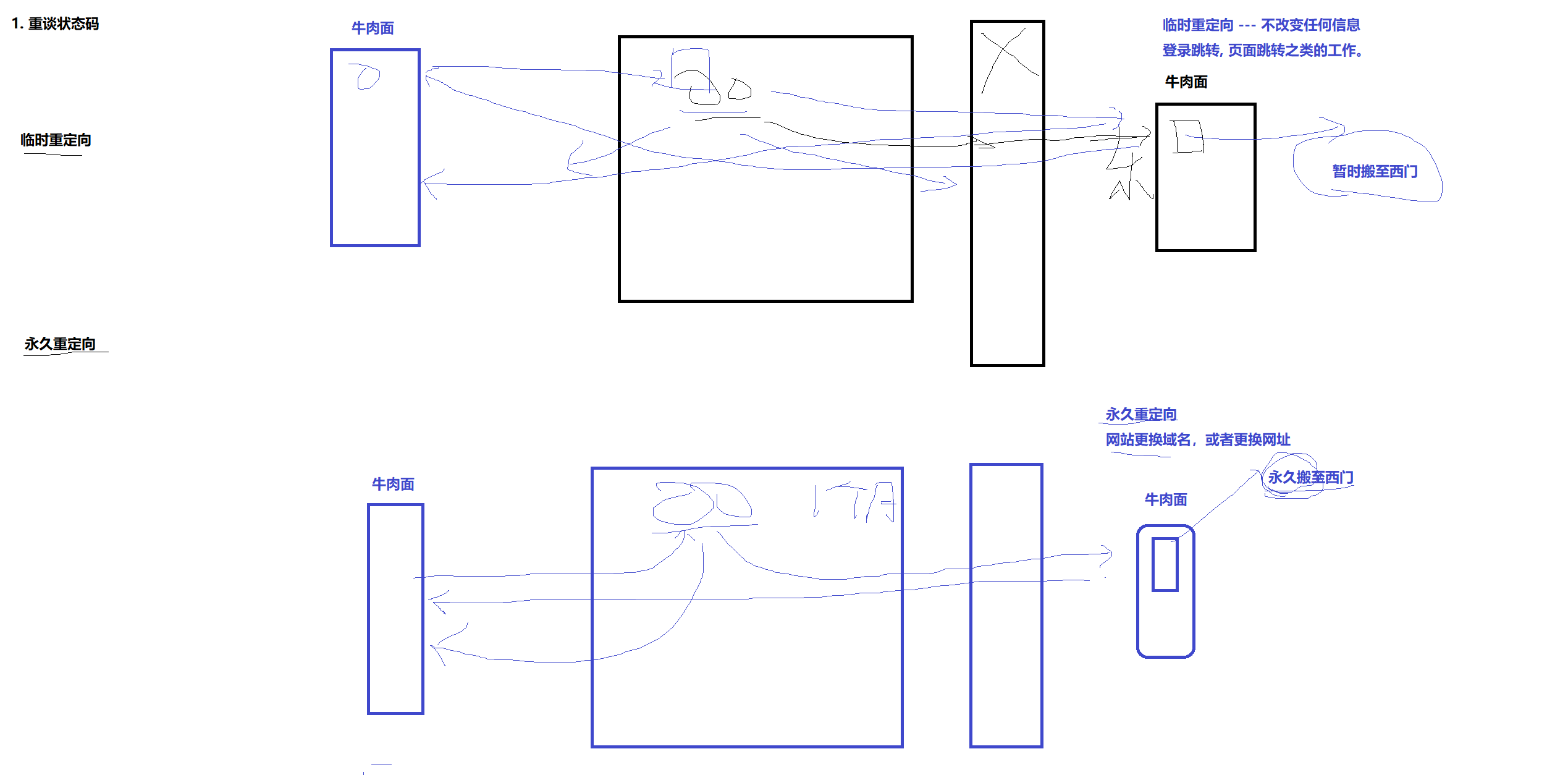
临时重定向:一家开在学校东门的牛肉面馆,因为道路施工尘土飞扬,临时搬到了学校的西门,并在原来的位置贴上了告示。有一天,小王想去吃牛肉面了,去了东门的位置,看了告示就转头去西门位置了。过了一个月,小王又想去吃牛肉面了,先去东门的位置。就是但由于之前告示上写的是临时搬去西门,这次他还
永久重定向:还是牛肉面馆,还是相同的原因,这次告示上写的是永久搬去西门位置。第一次,小王去吃牛肉面,先去东门,看了告示就转头去西门位置了。过了一个月,小王又想去吃牛肉面了,永久搬去西门。就是这次他直接去西门吃了,因为他记得告示内容写的
理解:
临时重定向:不改变任何信息(登录跳转,页面跳转)
永久重定向:网站更换域名,更换网址(搜索引擎更新网站链接)
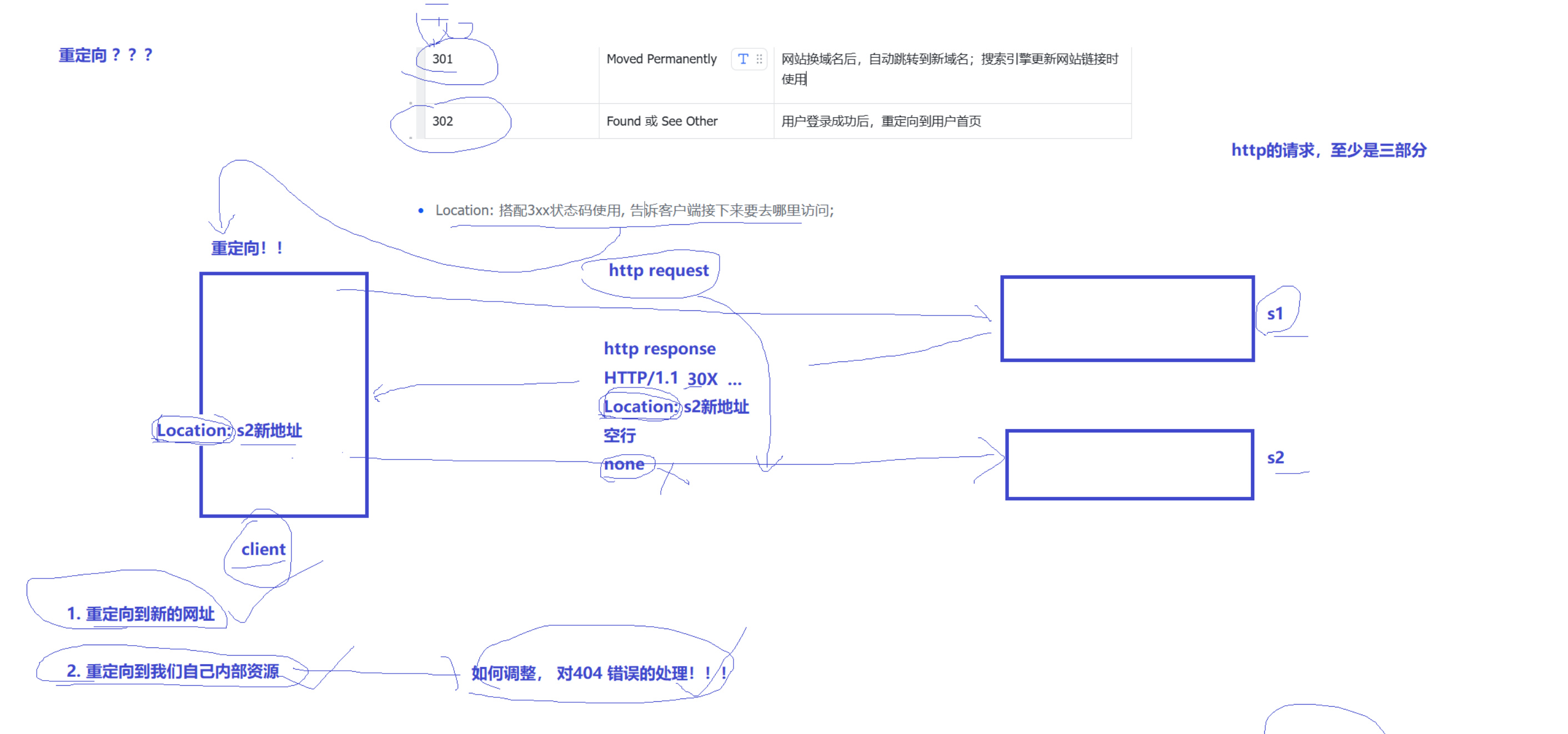
- 301,Moved Permanently,网站换域名后,自动跳转到新域名;搜索引擎更新网站链接时时候用。
- 302,Found 或 See Other,用户登录成功后,重定向到用户首页。
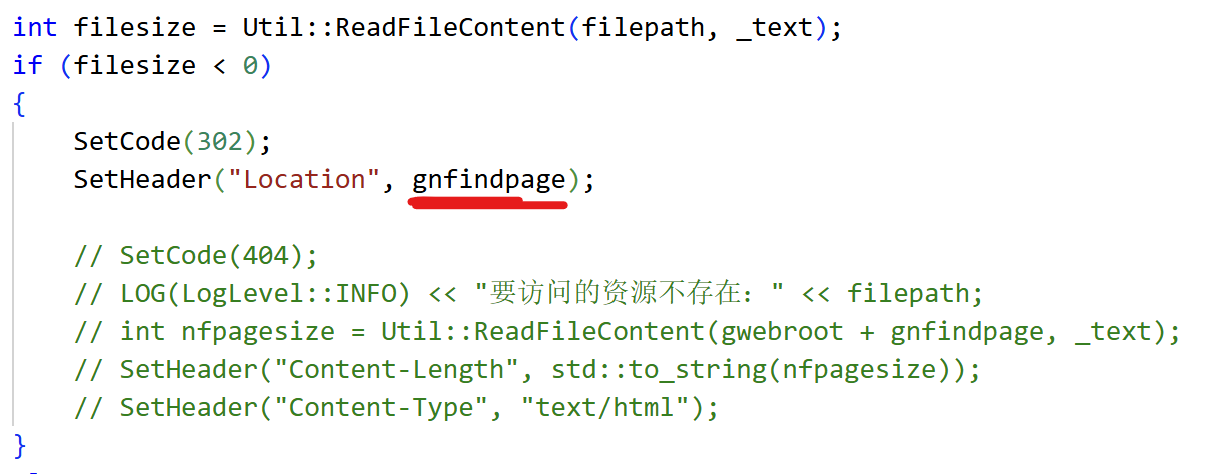
报头Location,记录着重定向的地址。
重定向:发送请求,接收到重定向响应后,客户端(浏览器)会分析报文,发现是30X,二次发送请求,url就用Location对应的地址。
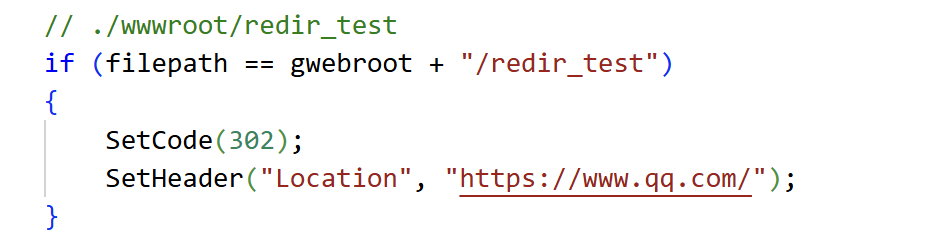
实验1:重定向到新的网址
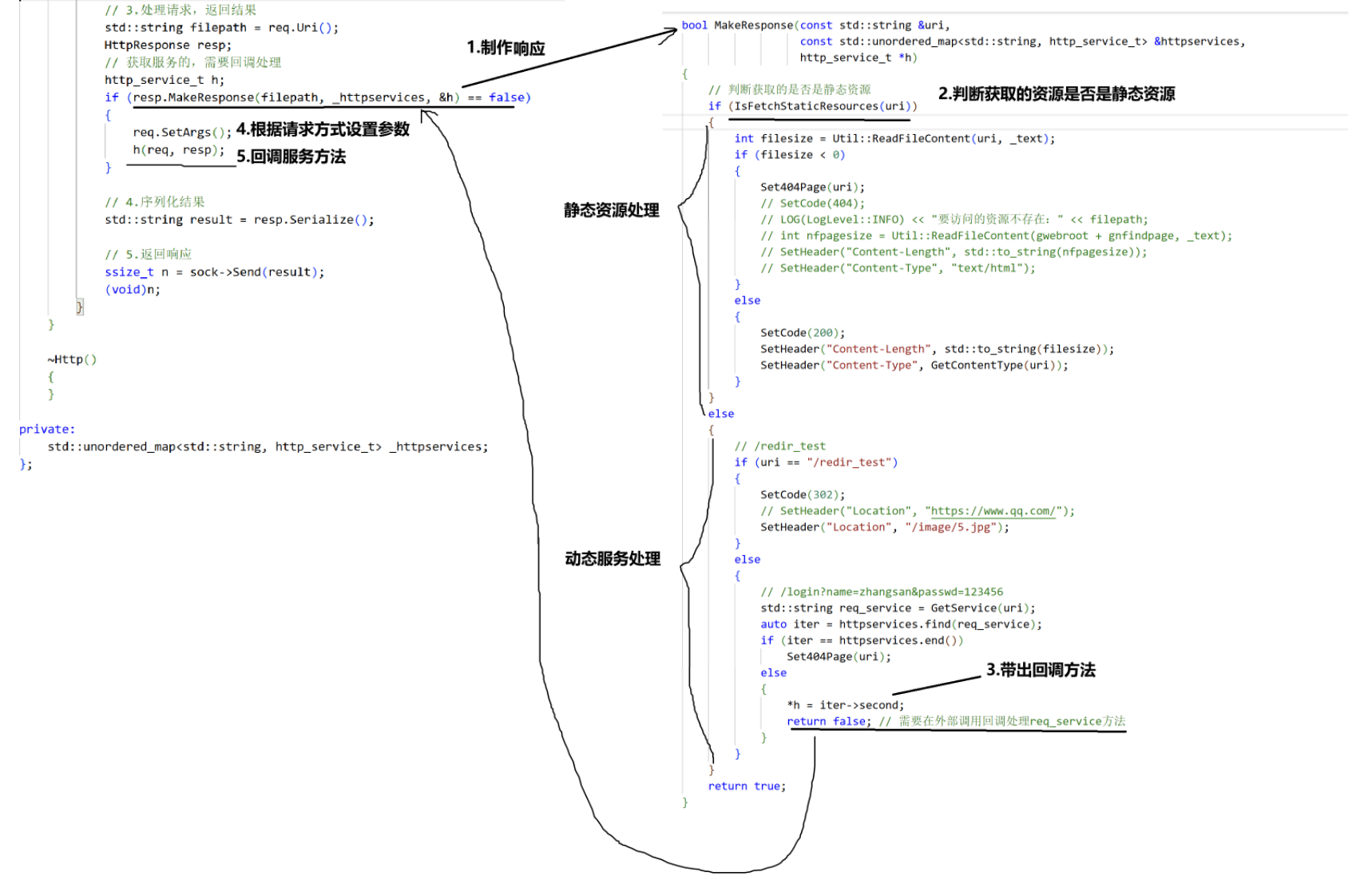
注意的点:需要对uri进行判断,判断其指向的是静态资源还是动态服务
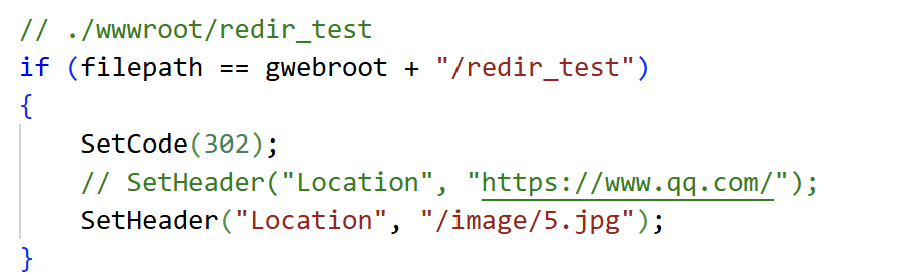
实验2:重定向到我们自己内部资源(允许调整对404错误的处理)
注意:重定向404时,只用带上相对于web根目录的相对路径就行了。


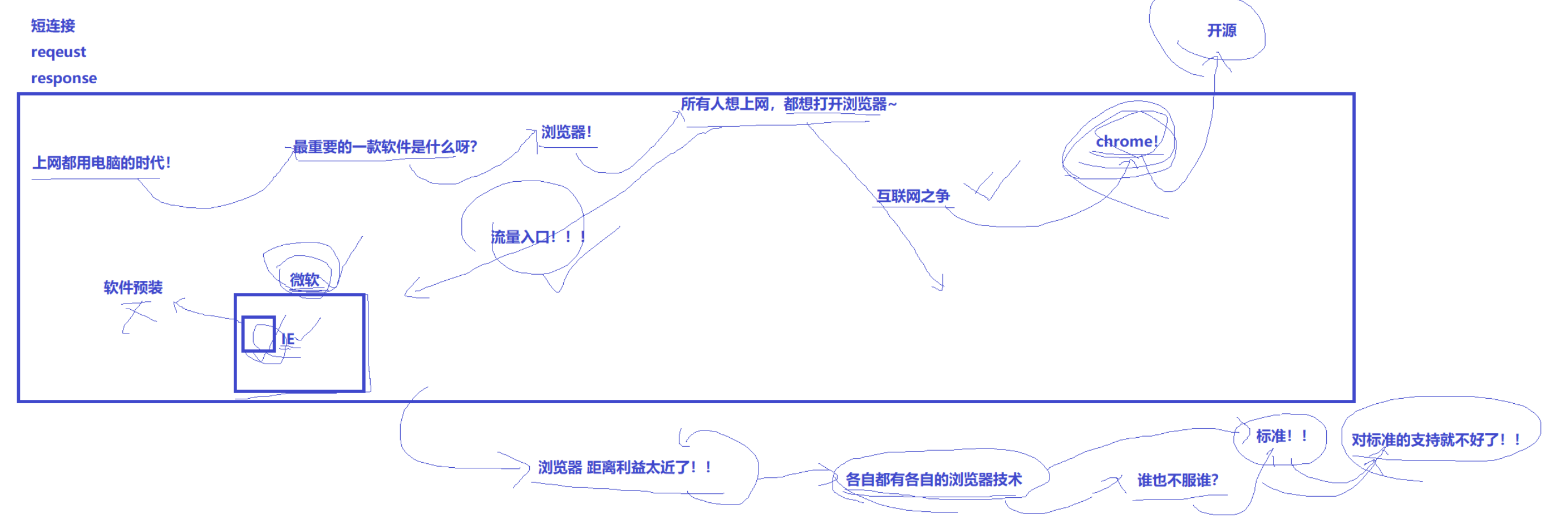
浏览器生态
背景:20多年前,上网都用电脑的时代 -> 最重点的一款软件 -> 浏览器 -> 所有人想上网,都得打开浏览器 -> 浏览器是流量的入口 -> 微软在做,谷歌也在做。微软本身有windows操作系统,且规模庞大,通过预装浏览器的方式,收益颇丰。谷歌为了对抗竞争,将自己开源了(开源也是一种商业手段)
浏览器距离利益太近了 -> 各自都有自己的浏览器技术 ->大家水平都很高 -> 谁也不服谁 -> 对于标准的支持就不太好了。
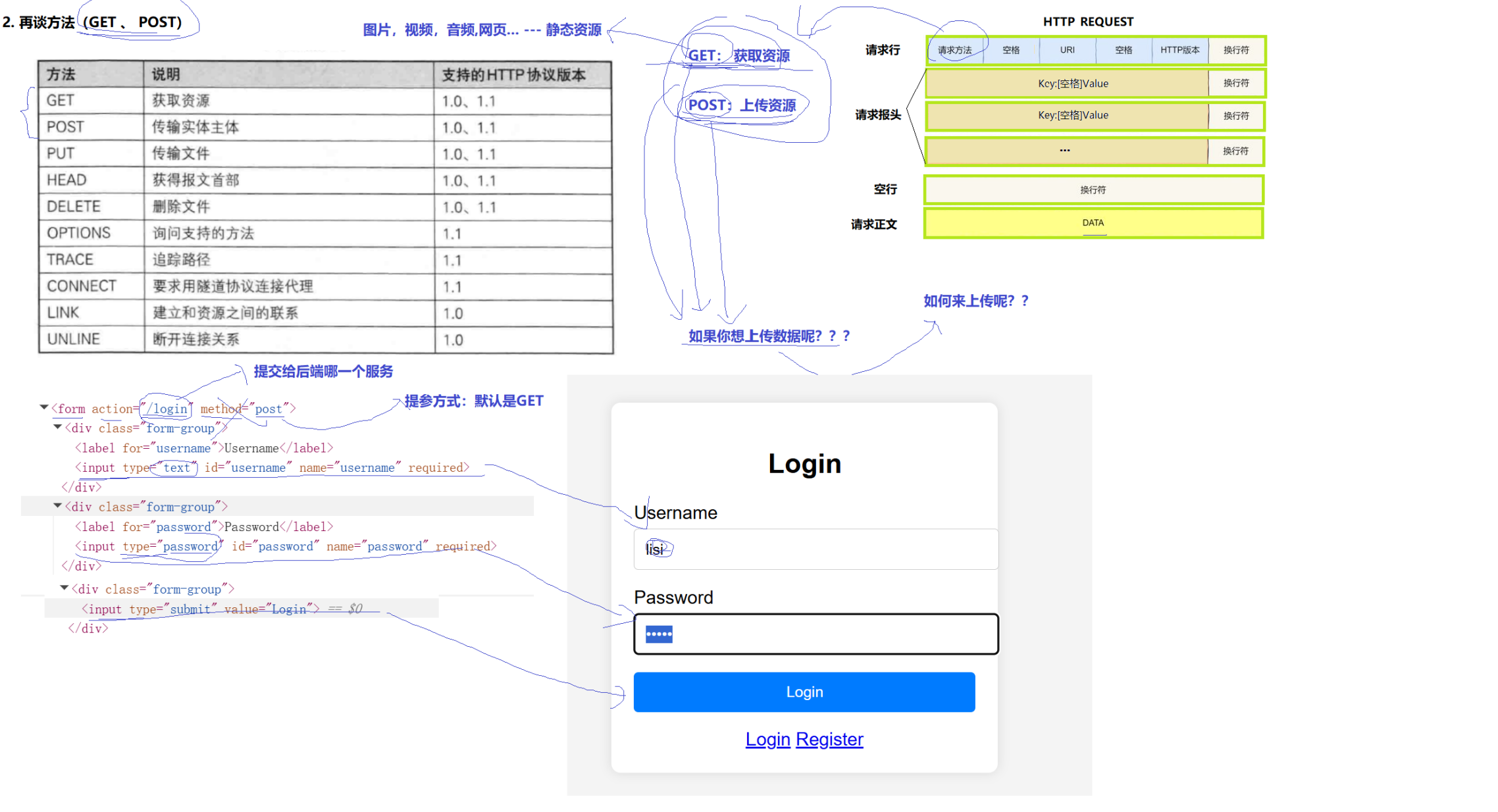
再谈方法(GET,POST)
GET:获取资源
POST:上传资源
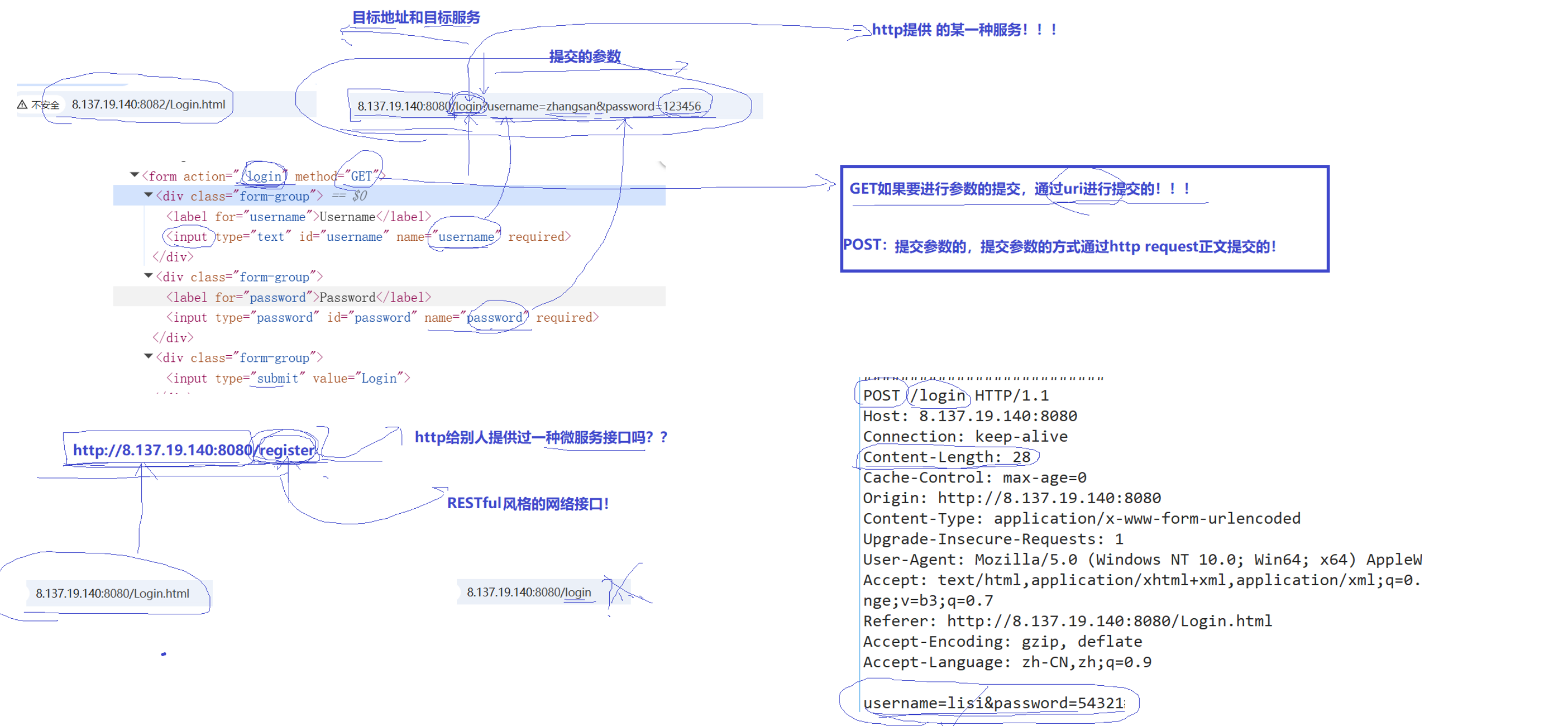
要是你想上传数据呢???如何上传??可能通过html的form表达来上传。
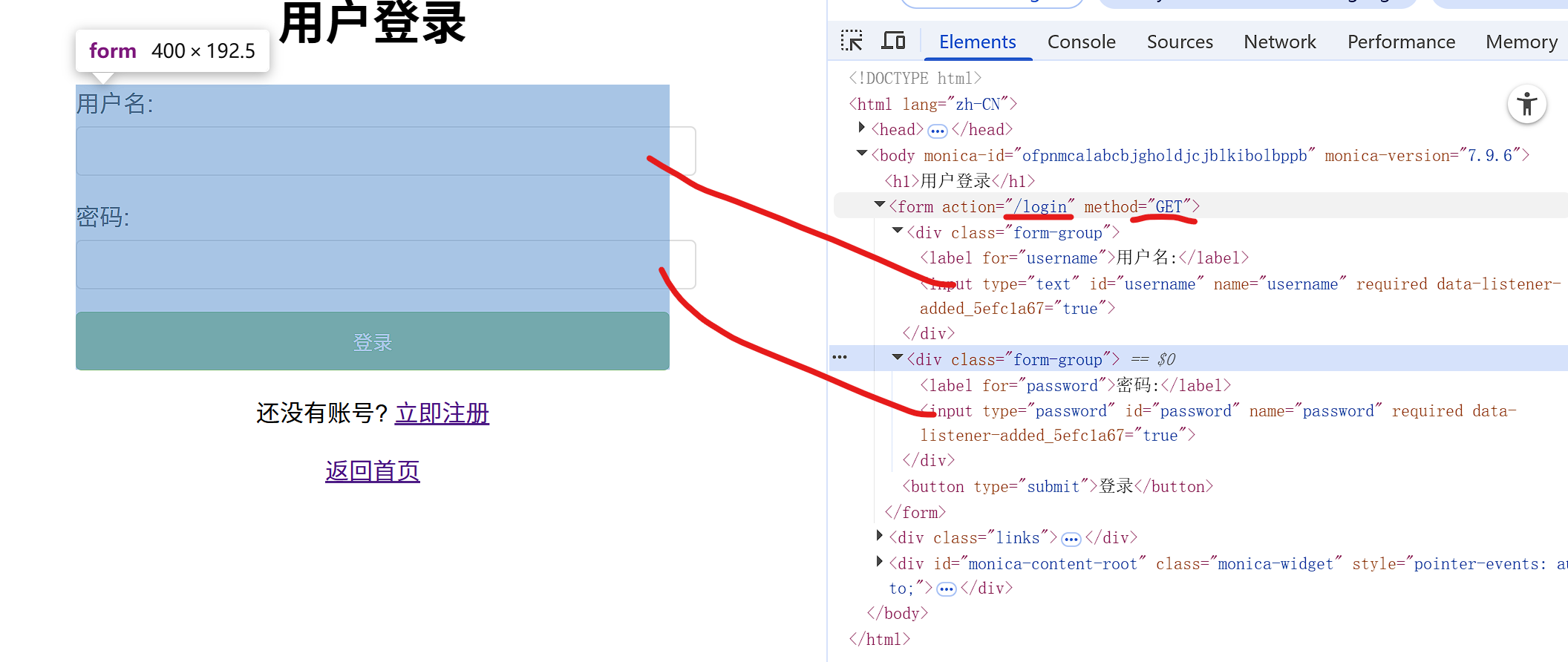
action="/login"表示想请求的服务,method="GET"表示请求方式
GET假如要进行参数提交,凭借uri进行提交的!
POST:提交参数的,提交方式是通过http request正文方式提交的!
可能根据uri中的 /register 注册指定方法,提供对应的服务。

GET和POST特点
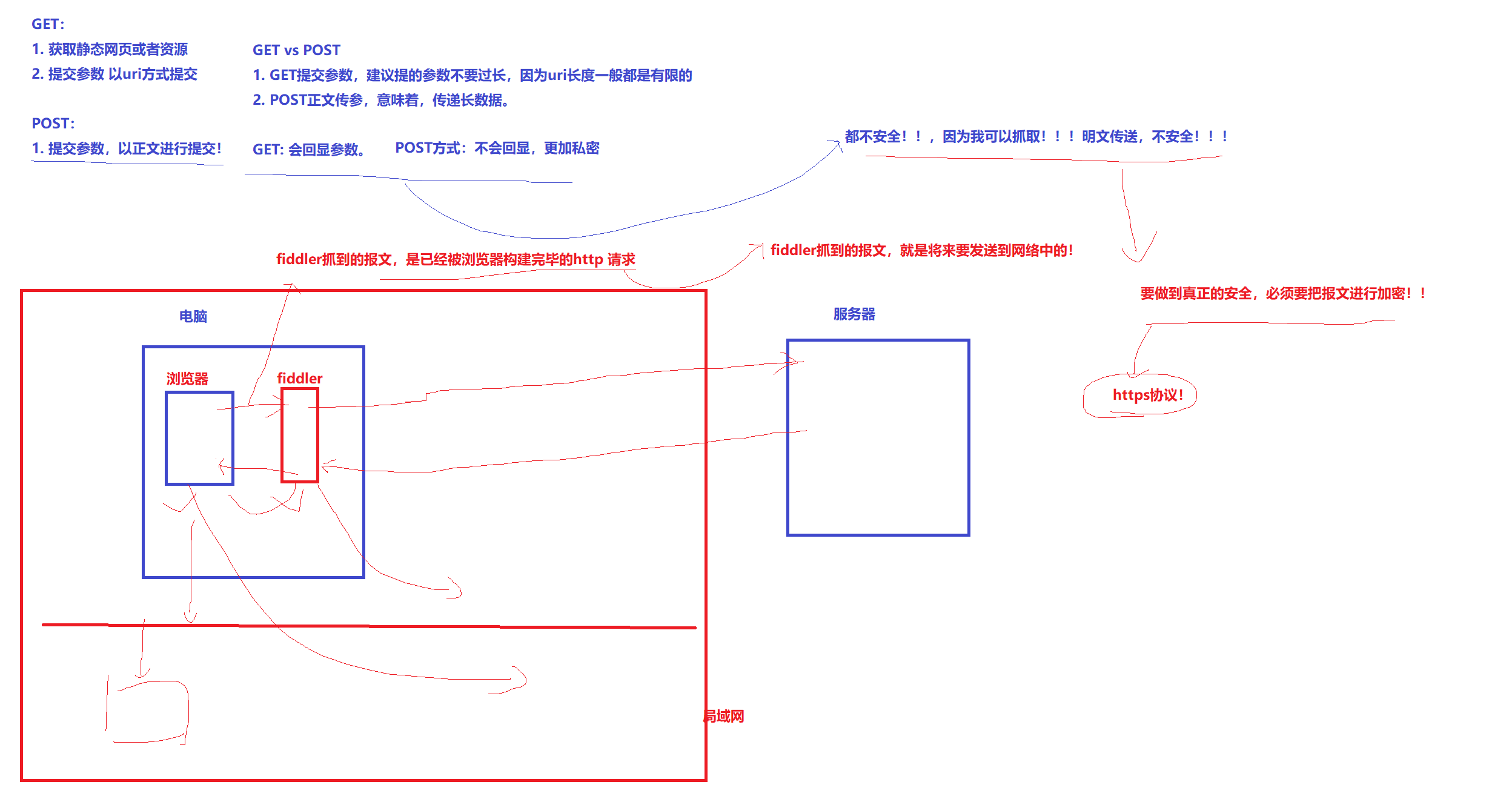
GET:
1)获取静态网页或者资源
2)提交参数以uri方式提交
POST:
提交参数,以正文进行提交
GET vs POST
1)GET提交参数,建议提的参数不宜过长,因为uri长度一般是有限的
2)POST正文传参,意味着传递长数据
POST方式:不会回显,更私密 -> 都不安全!因为行抓取,明文传输不安全 ->要做到真正的安全,必须对报文进行加密(https协议)
fiddler抓包软件原理:
截取浏览器发给服务端的请求,转发给服务器。收到来自服务器的响应后,发回给浏览器。为什么可以截取?因为fiddler和浏览器处于同一个局域网,发出报文局域网内所有主机都能收到。
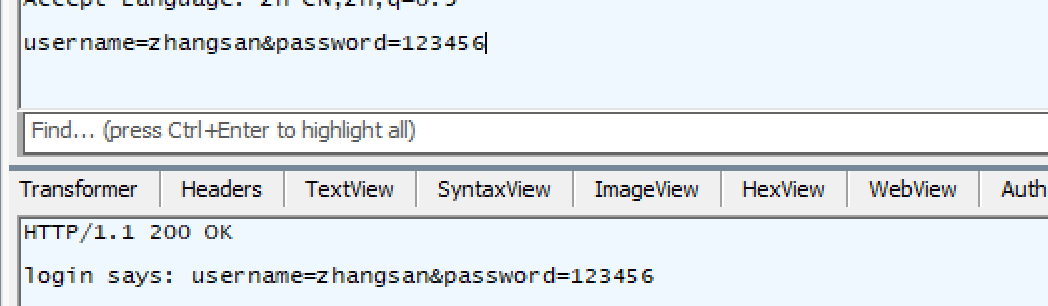
fiddler抓到的报文,是浏览器已经构建好的http请求->这个请求就是要发到网络中的,因此直接接收和转发即可。
GET请求服务可以套壳
GET,允许构造HTTP请求,填充参数,就可以套壳百度的/s检索技巧。就是例如:百度的/s方法,请求方式

短连接存在的困难
Connection报头,长连接。
多进程或者多线程来处理连接的话,每次处理完请求就关闭,一次处理一个请求。就是短连接存在的问题:如果tcpserver采用的图片等资源很多的话,消耗太大了。就是建立连接:tcp三次握手,accept,fork或者pthread_create,网页中有一张图片就要发送一次请求,要
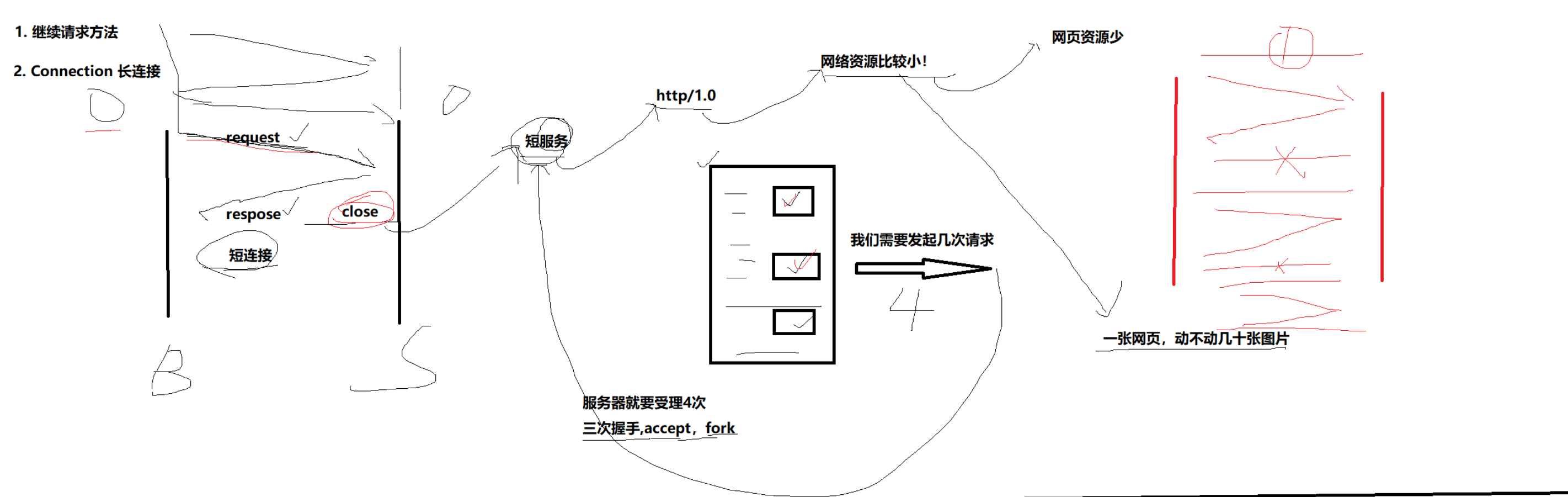
长连接
Connection:keep-alive,表示保持连接,要复用连接(长连接)
Connection:close,表示请求/响应完后,关闭连接(短连接)
长连接:一条连接就可以交互非常多的请求(HTTP/1.1)(网络版本计算器)
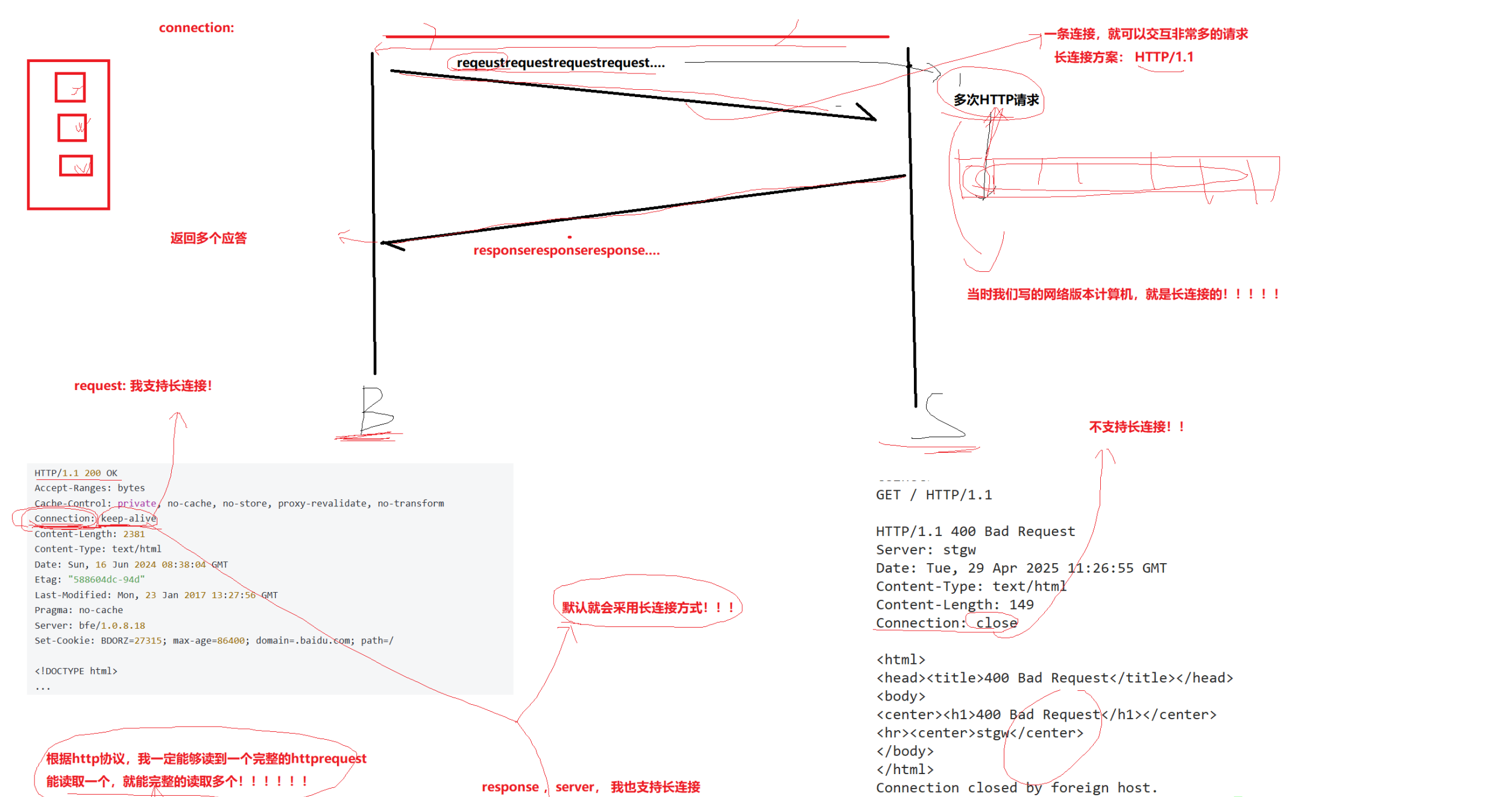
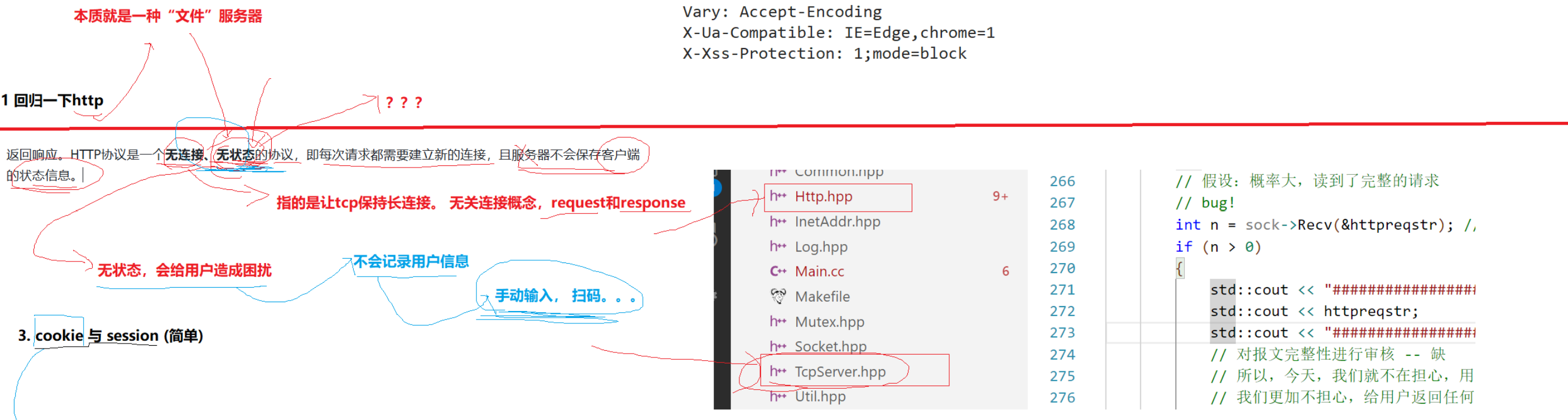
回归HTTP
HTTP协议是一个无连接,无状态的协议,即每次请求都需要重新建立新的连接,且服务器不会保存客户端的状态信息。
- 无连接:让tcp保持长连接,通信双方约定好的结构体)就是无关连接概念,只和request和response有关(协议本质
- 无状态:会给用户造成困扰 ->不会记录用户信息-> 登录手动输入,扫码
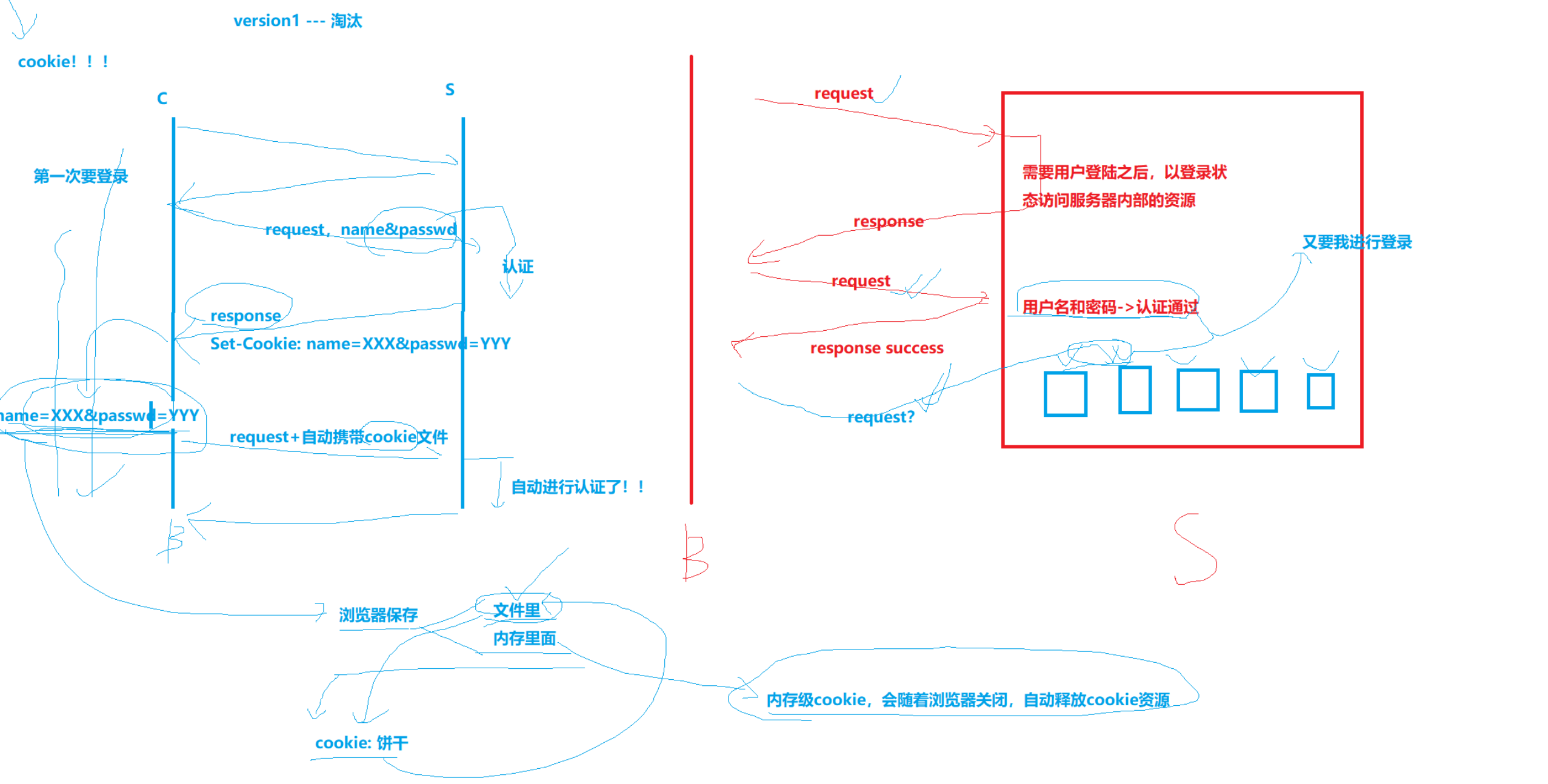
cookie和session
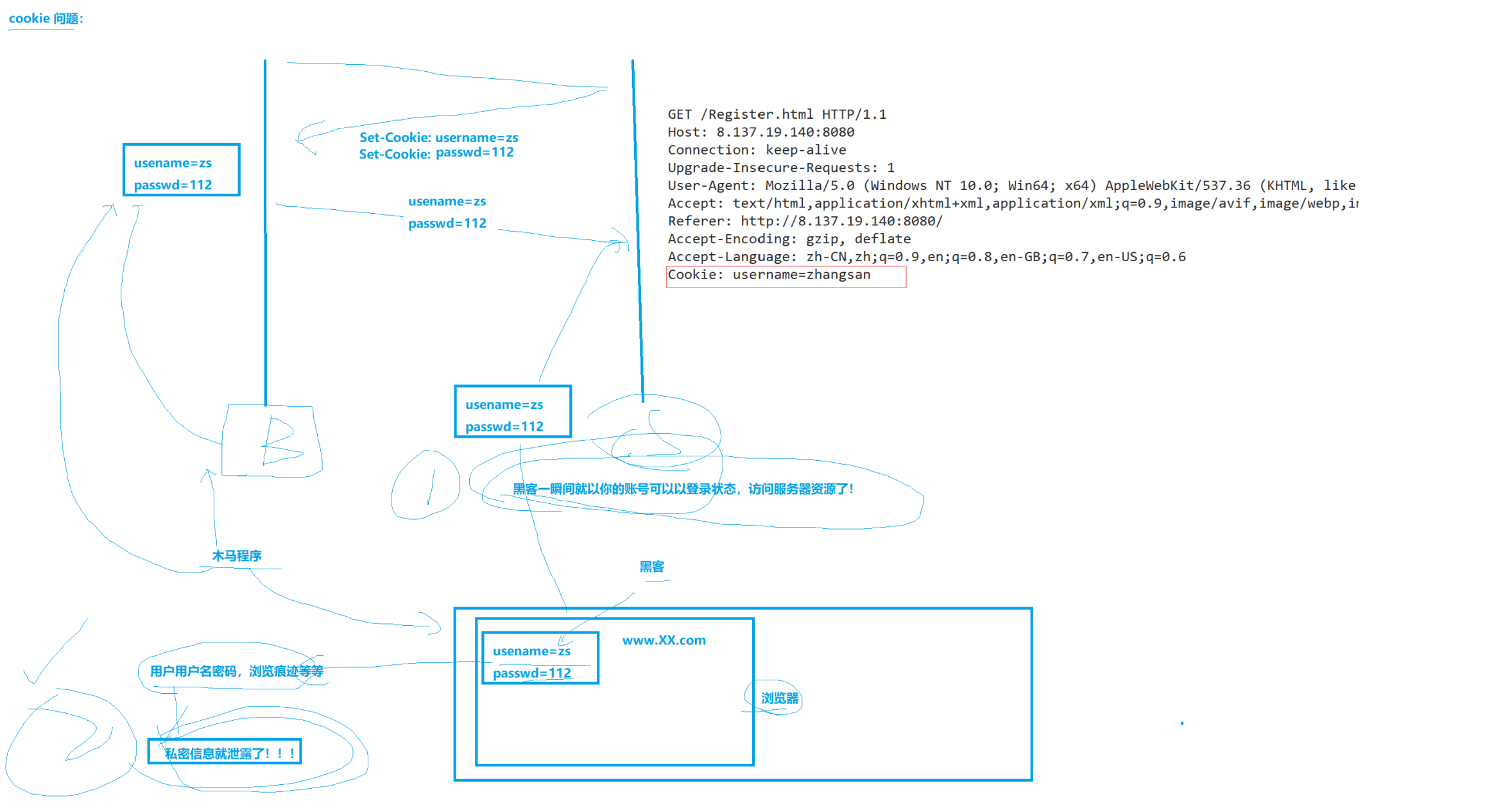
cookie引入的原因:HTTP服务器不会记录客户端的状态信息,要是是要求保持登录状态才能浏览的网页,用户每次跳转到新的页面,都要重新登录。
cookie原理:第一次登录时要求手动输入,返回响应的报头中有Set-Cookie字段,以及对应的值。浏览器收到响应,浏览器会保存Set-Cookie的内容到文件 或者 内存(内存cookie,会随着浏览器关闭,自动释放)。下一次请求这个资源时,服务器发送请求会自动携带cookie材料(Cookie报头携带内容),这样就不用用户主动输入了。
新的技能会带来新的问题,这时又要有新的技术去解决(互斥锁线程饥饿问题用条件变量同步解决)。
cookie问题:Cookie是明文传输在HTTP报头的通过。若是有一个黑客,用抓包工具抓到HTTP请求,1)黑客就能够你的账号进行登录,访问服务器资源了 2)用户名和密码是明文的,私密信息就泄露了!(例如转账等操作)
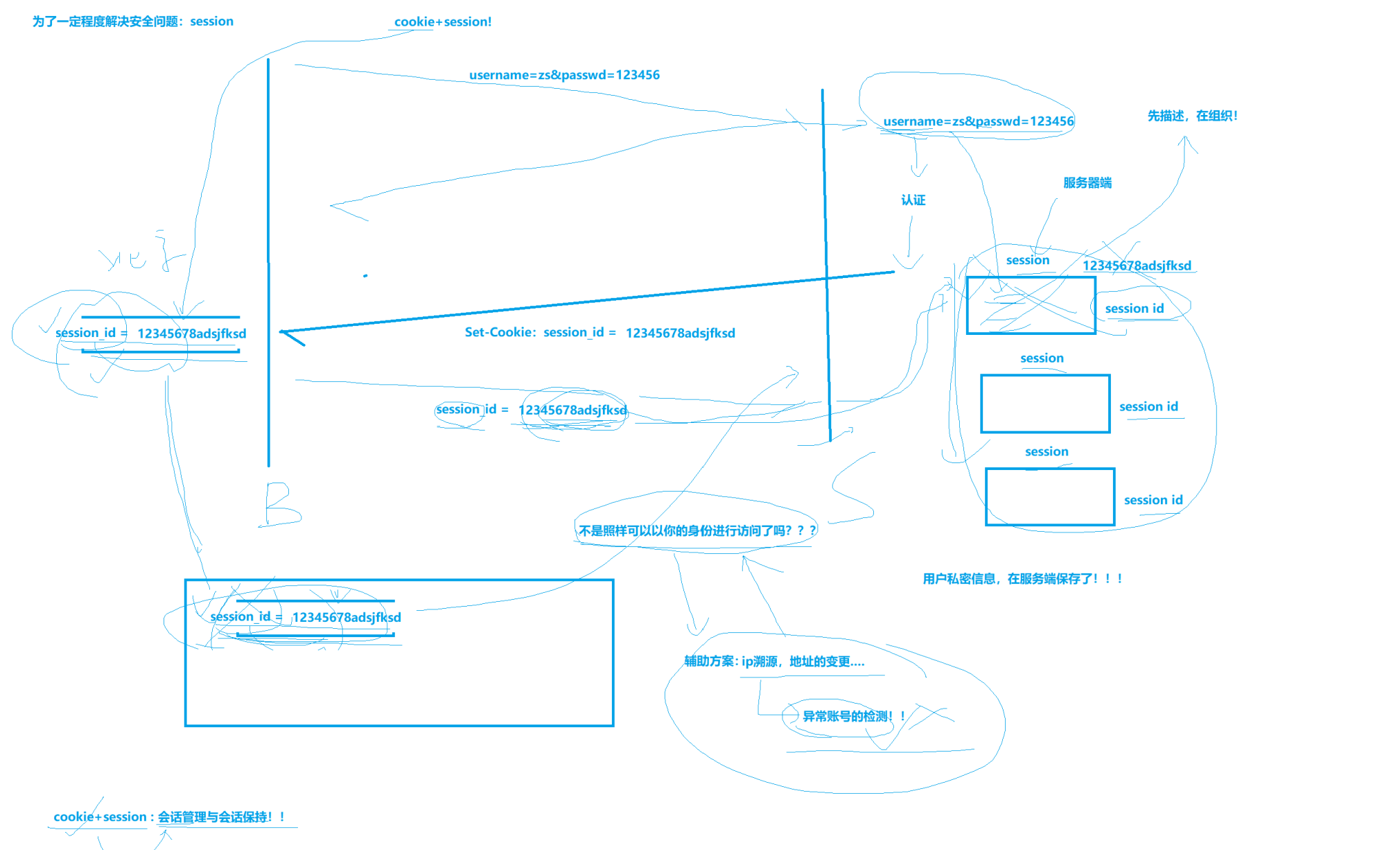
为了一定程度解决安全难题,session工艺。
version2:cookie+session(会话管理与会话保持)
cookie+session:服务器在收到客户端的请求,形成一个文件叫做session,并有其对应的唯一session id值(这个id值允许借助毫秒级时间戳+随机数,哈希函数等给出),这个材料会记录用户信息(用户私密信息,在服务端保存了)。响应时用Set-Cookie把这个session id发送给浏览器,浏览器保存cookie到文件/内存中。下一次请求只用把该session id携带上,这样就不用用户再次输入了,且账号密码不是明文传输了,更安全了。
貌似还是有难题:此时有一个黑客,经过抓包工具,拿到了session id,还是可能构建请求发送给服务器,以你的身份进行访问。没错,但是相对于纯cookie,他的密码和账号不是明文了,对于转账支付等场景就解决了。除此之外,还有辅助方案:ip资源,地址的变更(可以代理服务器处理),还有异常账号检测机制(检测账号异常情况,例如给好久没聊天的好友发送大量信息)
session的管理:服务端假设拥护session,就会存在大量session文件,怎么管理这些session文件?先描述,在组织。
浏览器对于请求的处理
80,但这并不意味着它只能使用80端口。就是HTTP协议的默认端口
你可以在浏览器中输入
xxx.xx.xx.xx:8080,浏览器会向目标服务器的8080端口发送一个HTTP请求。
xxx.xx.xx.xx:8080HTTP请求,发往8080端口 你的情况:无明确协议(默认HTTP),但有明确端口(8080)。
http://xxx.xx.xx.xxHTTP请求,发往80端口 明确协议,但无端口,使用HTTP默认端口80。
http://ip:8080,浏览器会根据这个url做解析,发送请求给8080端口,http不是只能采用80端口。
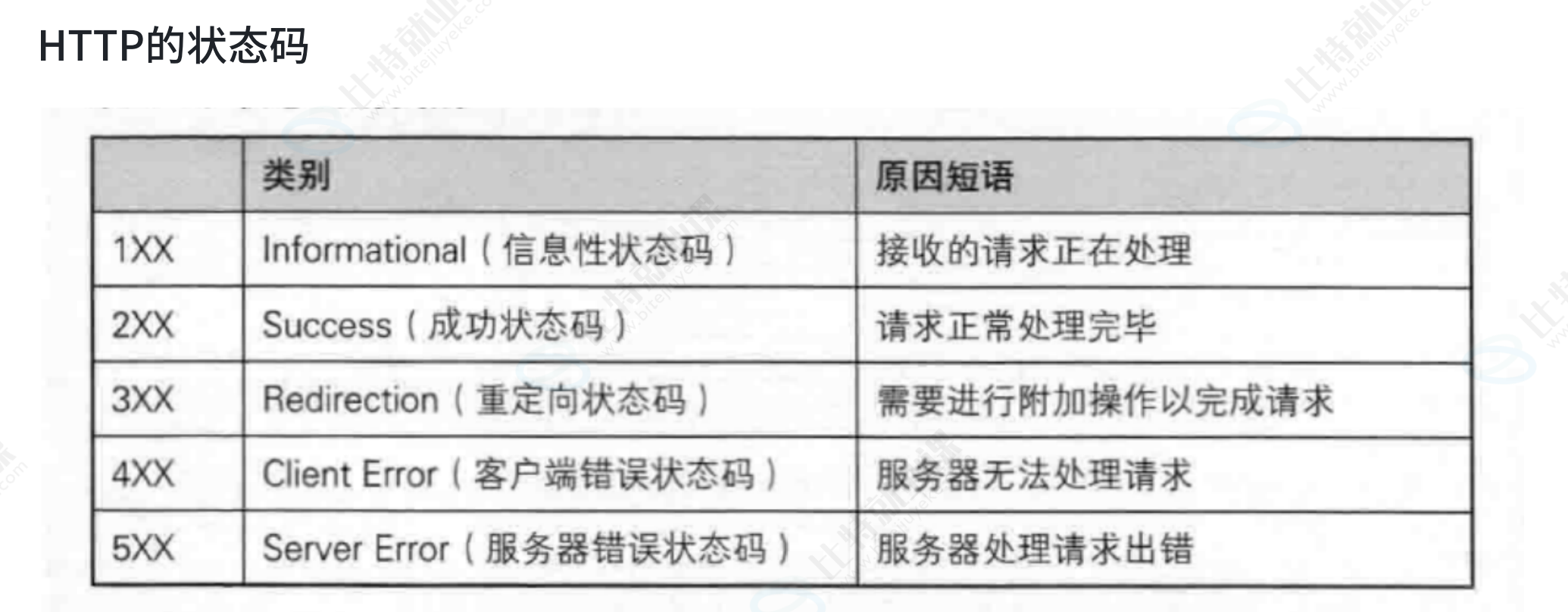
HTTP状态码总结:
1XX:例如上传大档案的时候
4XX:例如没有权限,没有资源,提交表单格式不正确
5XX:服务器处理请求错误,例如服务器崩溃。
代码:
Linux-remote: linux远程仓库![]() https://gitee.com/its-quite-six/linux-remote/tree/master/25_9_23/HTTP
https://gitee.com/its-quite-six/linux-remote/tree/master/25_9_23/HTTP