一、前言
在征程 6 工具链的量化精度调优实践中,当 Matmul/Conv 算子的两个输入皆为量化敏感算子时,PTQ 与 QAT 各自面临着难以克服的棘手困境。
在 PTQ 流程里,为了实现双 int16 输入的支持,工作人员不得不借助脚本将原本结构单一的 Matmul/Conv 算子拆解为 2 个 conv + add 算子,随后还要围绕这两个新算子进行一系列复杂且细致的量化配置。这一过程不仅涉及到 onnx 模型的修改,更需要投入人力成本进行反复的测试和验证,操作较为繁琐。
反观 QAT,由于受到技术实现方面的限制,在面对同样的情况时,仅能将其中更为敏感的一个输入配置为 int16,而另一个输入仍只能维持 int8 计算。这种妥协的做法导致在部分对精度要求较高的复杂场景下,模型的精度难以达到预期要求,成为制约模型性能进一步提升的瓶颈,使得许多具有潜在应用价值的模型因为精度问题而无法在实际生产中得到有效应用。
值得欣喜的是,随着工具链技术的持续迭代和不断创新,最新的量产版本 OE 3.2.0 带来了一项重大更新 ——Gemm 类算子对双 int16 的支持(需注意,int32 高精度输出的算子暂不支持)。这一更新犹如一场及时雨,极大地拓展了量化配置的灵活性,为提升模型精度开辟了一条全新的路径。其支持范围广泛,涵盖了 PTQ 中的 Conv、MatMul 算子,以及 QAT 中的 Conv2d、Linear、Matmul 算子,几乎覆盖了深度学习模型中常用的核心计算算子,能够满足多种不同模型结构的量化需求。
然而,新功能的引入也带来了新的问题和挑战:当因 Gemm 类算子引发精度问题时,PTQ 和 QAT 应如何精准定位问题算子,并进行合理的双 int16 配置呢?
这正是本文即将深入探讨的核心内容。我们将详细剖析 PTQ 和 QAT 链路下双 int16 配置的完整流程,包括如何利用精度 debug 工具准确识别出需要配置为双 int16 的敏感算子,以及在 yaml 文件或代码中进行具体配置的实操步骤和注意事项。通过这些内容的讲解,助力读者在实际工作中能够高效、准确地运用这一强大功能,突破量化精度调优过程中的技术壁垒,让模型在保证高效运行的同时,也能达到理想的精度水平。
二、PTQ
2.1 定位需要配置为双 int16 的算子
一般来说,当全 int8 量化精度满足不了需求后,我们才会考虑配置 int16,那么在什么场景下我们需要配置双 int16 呢?
运行精度 debug 工具的 hmct-debugger get-sensitivity-of-nodes -n 'activation' 和 hmct-debugger get-sensitivity-of-nodes -n 'weight' 后,某个 conv 算子的敏感度均居于前列;
同理,运行精度 debug 后,Matmul 算子的两个输入敏感度都居于前列。
工具链用户手册上有非常完整的精度 debug 工具使用流程,如下所示:
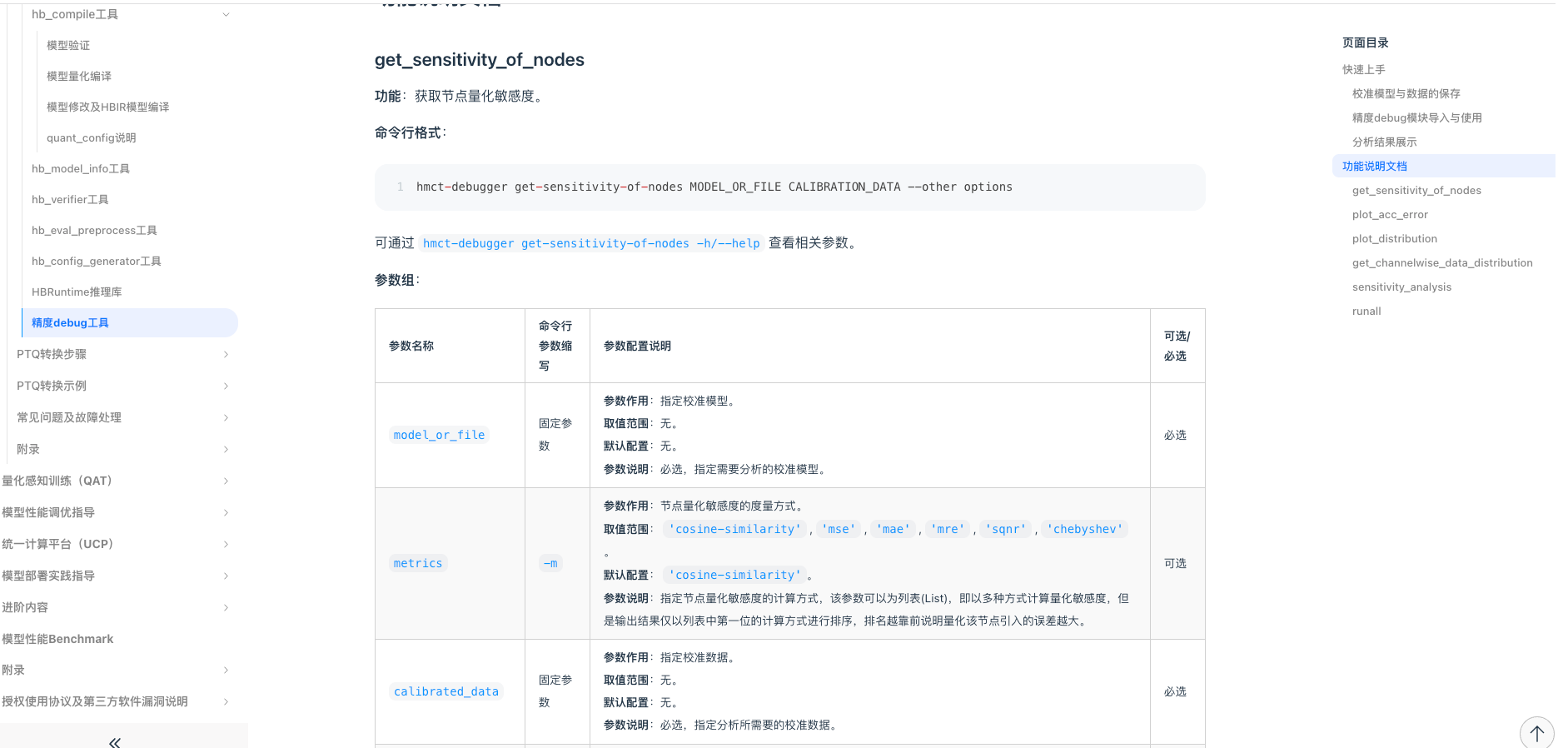
2.2 PTQ 双 int16 配置示例
确定两个输入都敏感的 Matmul/Conv 算子后,我们需要在 yaml 中对其做双 int16 的精度配置,配置示例如下:
calibration_parameters:quant_config: {// 配置模型层面的参数"model_config": {// 一次性配置所有节点的输入数据类型"all_node_type": "int8",// 配置模型输出的数据类型"model_output_type": "int8",},"node_config":{"Conv_1":{"input0": "int16","input1": "ec"},"Matmul_2":{"input0": "int16","input1": "ec"},}
}
ec 全称为 error compensate, 是一种通过创建相同算子来补偿特定算子 int8 量化精度损失的方案。当前仅支持如下算子, 其他算子配置不生效。
- Conv 和 ConvTranspose 算子的权重输入(通过 node_config 的三级参数 input1 指定)。
- MatMul 算子的任一输入(通过 node_config 的三级参数 input0 或 input1 指定)。
- GridSample 和 Resize 算子的第 0 个输入(通过 node_config 的三级参数 input0 指定)。
三、QAT
3.1 定位需要配置为双 int16 的算子
与 PTQ 类似,需要先使用精度 debug 工具获得敏感度列表,当 conv/linear 算子的 activation 和 weight 都处于敏感度列表前列时,则考虑将此算子配置为双 iint16,Matmul 算子则需要其两个输入节点都处于敏感度前列。
QAT 精度 debug 工具使用教程可以参考工具链手册如下章节:

QAT 精度 debug 工具的敏感度列表如下所示:
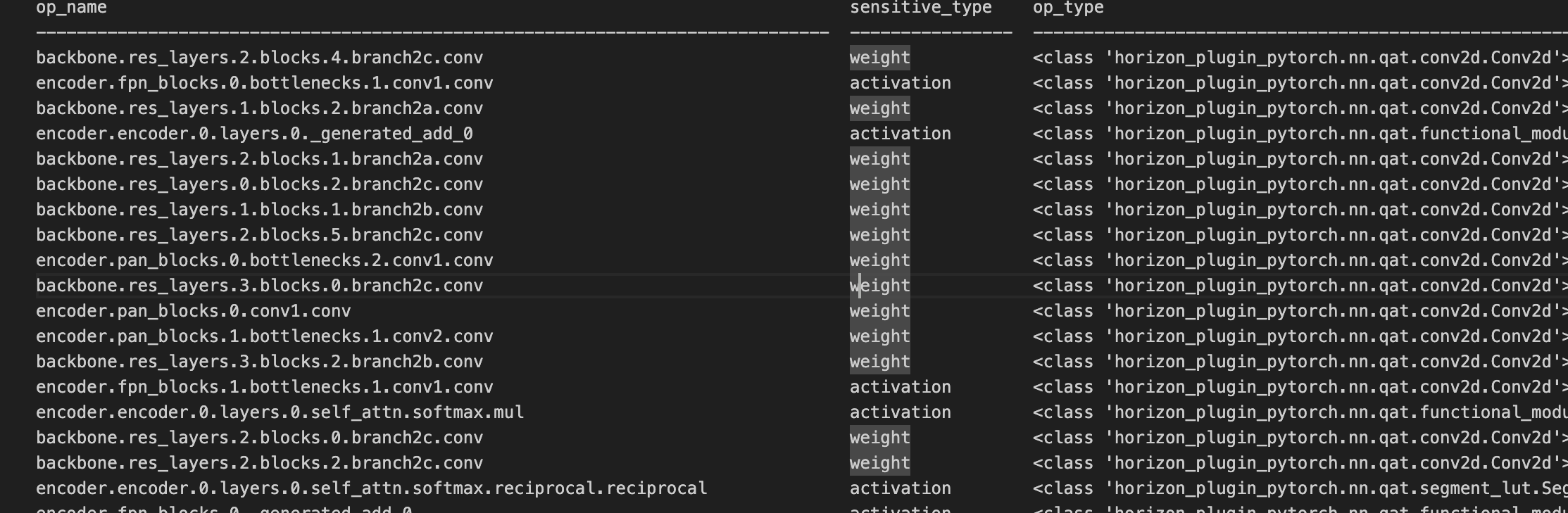
3.2 QAT 双 int16 配置示例
根据上图的敏感度列表,我们可以看出 backbone.res_layers.2.blocks.4.branch2c.conv 是 weight 敏感的算子,下面我们就以这个算子为例进行双 int16 的配置,如下所示:
from horizon_plugin_pytorch.quantization import prepare,set_fake_quantize,FakeQuantState,get_qconfig
from horizon_plugin_pytorch.dtype import qint8,qint16
from horizon_plugin_pytorch.quantization.qconfig_template import default_calibration_qconfig_setter
from horizon_plugin_pytorch.quantization.fx.graph_optimizers import QconfigCanonicalizer,FallbackStrategyVersionfloat_model.eval()
#构建输入feature和weight 双int16的qconfig
w16a16_qconfig=get_qconfig(observer=MSEObserver,in_dtype=qint16,weight_dtype=qint16,out_dtype=qint8)
#必须要配置回退逻辑版本
QconfigCanonicalizer.set_fallback_strategy_version(FallbackStrategyVersion.V2)
calib_model = prepare(copy.deepcopy(float_model),example_inputs=example_input,qconfig_setter=(ModuleNameQconfigSetter({ "backbone.res_layers.2.blocks.4.branch2c.conv":w16a16_qconfig, }),default_calibration_qconfig_setter),check_result_dir="./")
linear 算子的双 int16 输入配置和 conv 相同,为了保证 linear/conv 的激活输入是 int16,建议直接配置上层算子的输出为 int16。
Matmul 的双 int16 输入配置和 conv 有所不同,这里举例说明。比如存在两个输入都敏感的 matmul 算子 matmul_id_0,其两个输入的算子名称分别是 matmul_id_0_input0 和 matmul_id_0_input1,那么此算子的双 int16 配置为:
from horizon_plugin_pytorch.quantization import prepare,set_fake_quantize,FakeQuantState,get_qconfig
from horizon_plugin_pytorch.dtype import qint8,qint16
from horizon_plugin_pytorch.quantization.qconfig_template import default_calibration_qconfig_setter
from horizon_plugin_pytorch.quantization.fx.graph_optimizers import QconfigCanonicalizer,FallbackStrategyVersionfloat_model.eval()
w8a16_qconfig=get_qconfig(observer=MSEObserver,out_dtype=qint16)
#必须要配置回退逻辑版本
QconfigCanonicalizer.set_fallback_strategy_version(FallbackStrategyVersion.V2)
calib_model = prepare(copy.deepcopy(float_model),example_inputs=example_input,qconfig_setter=(ModuleNameQconfigSetter({ "matmul_id_0_input0":w8a16_qconfig, "matmul_id_0_input1":w8a16_qconfig, }),default_calibration_qconfig_setter),check_result_dir="./")
这里有 3 点特别需要注意:
- 必须要配置 QconfigCanonicalizer.set_fallback_strategy_version(FallbackStrategyVersion.V2),从而支持 gemm 的双 int16;
- 在配置双 int16 时,hbdk4-compiler 版本至少需要是 4.3.3,即 OE3.2.0 集成的正式对外版本;
- 在将 conv/matmul/linear 的输入配置为双 int16 后,其输出暂不支持再配置为 int32 高精度输出。