Python--Numpy
import numpy as np
1、扩展程序库(维度数组与矩阵运算、针对数组运算提供大量的数学函数库)
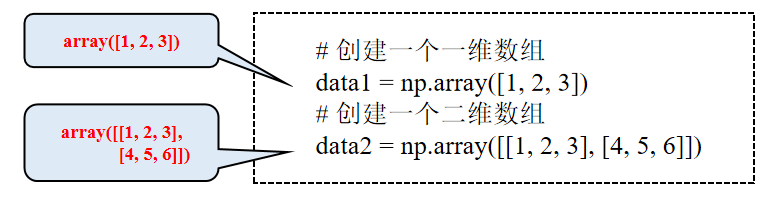
2、N维数组对象对象:ndarray(别名array,用于存放同类型元素的多维数组
,以 0 下标为开始进行集合中元素的索引。
3、属性:

4、创建Numpy数组:
使用array()函数,在调用该函数时传入一个列表或者元组。
linspace 函数用于创建一个一维数组,数组是一个等差数列构成的

logspace 函数用于创建一个对数等比数列

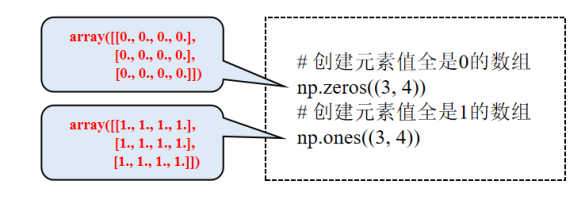
zeros()函数创建元素值都是0的数组;通过ones()函数创建元素值都为1的数组。
empty()函数创建一个新的数组,该数组只分配了内存空间,它里面填充的元素都是随机的。

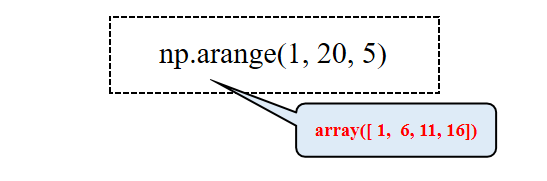
arange()函数可以创建一个等差数组,它的功能类似于range(),只不过arange()函数返回的结果是数组,而不是列表。根据 start 与 stop 指定的范围以及 step 设定的步长,生成一个 ndarray
有些数组元素的后面会跟着一个小数点,而有些元素后面没有,比如1和1.,产生这种现象,主要是因为元素的数据类型不同所导致的。
5、数据类型:
NumPy的数据类型是由一个类型名和元素位长的数字组成。(例如float64)
常用的数据类型如右表所示:
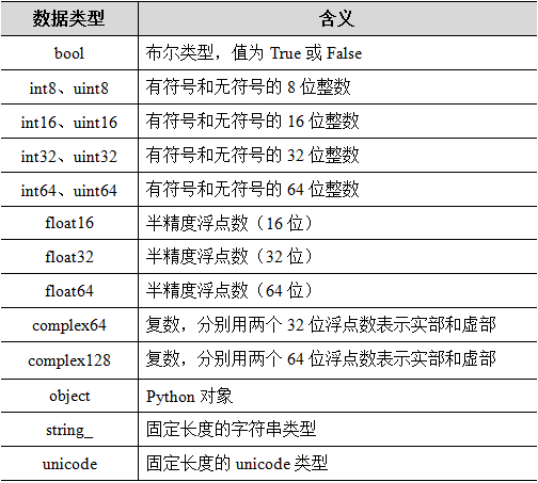
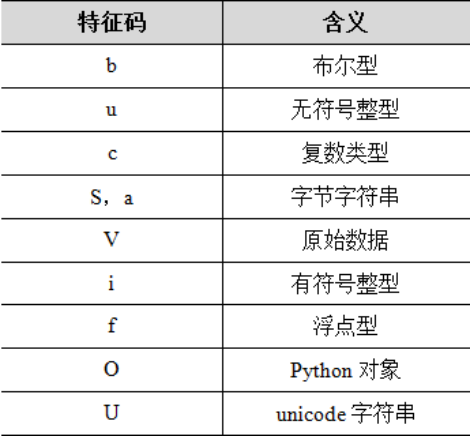
每一个NumPy内置的数据类型都有一个特征码,它能唯一标识一种数据类型。
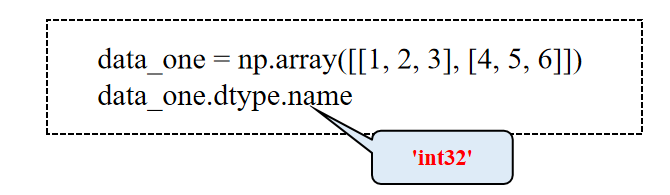
ndarray.dtype可以创建一个表示数据类型的对象,如果希望获取数据类型的名称,则需要访问name属性进行获取。
数据类型可以通过astype()方法进行转换。

6、数组运算
7、ndarray的索引和切片、排序
索引
一维数组

多维数组

想获取二维数组的单个元素,则需要通过形如“arr[x,y]”的索引来实现,其中x表示行号,y表示列号。
切片
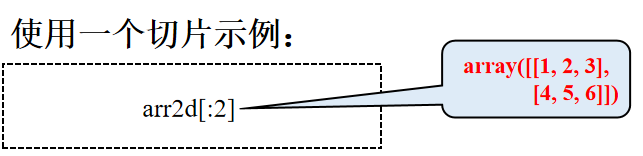
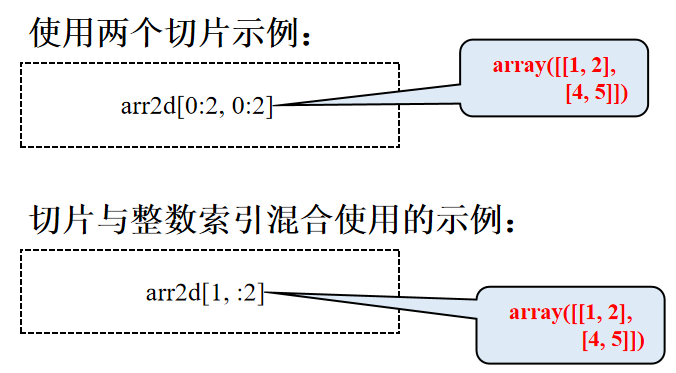
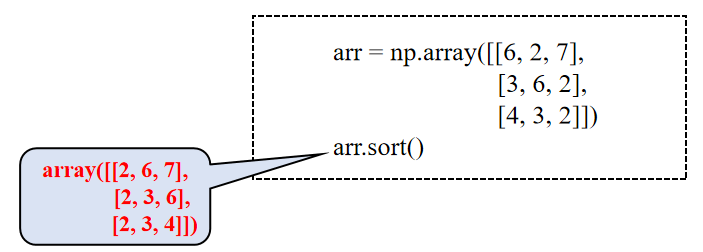
排序
可以通过sort()方法实现
检索
all()函数用于判断整个数组中的元素的值是否全部满足条件,如果满足条件返回True,否则返回False。

any()函数用于判断整个数组中的元素至少有一个满足条件就返回True,否则就返回False。

8、数组的转置
数组的转置指的是将数组中的每个元素按照一定的规则进行位置变换。
T属性:进行轴对换而已。
transpose()方法:对数组的shape进行调换时,需要以元组的形式传入shape的编号,比如(1,0,2)。

只需要转换其中的两个轴,这时可以使用swapaxes()方法实现,该方法需要接受一对轴编号,比如(1,0)。

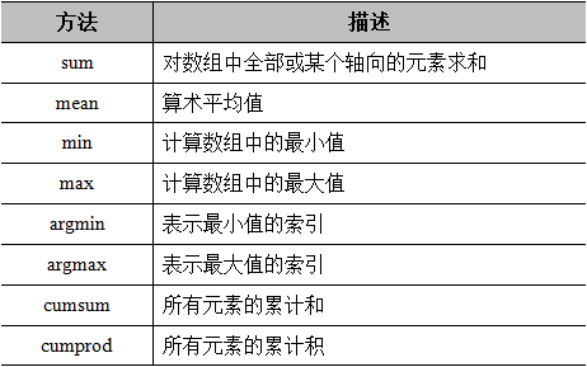
9、统计函数
NumPy 数组中提供了一些简单的统计函数,可以帮助我们计算数组的最大、最小值、平均值、中位数等。
最大、最小值¶
可以使用.max()/.min()或np.amax()/np.amin(),计算数组的最大最小值
a = np.random.randint(low=0,high=99, size=(7,9))
print (a,"\n",a.max(),"\n",a.min())
平均值
可以使用np.mean()/np.average()或.mean()方法获取数组中所有元素的均值
a.mean()
中位数
使用np.median()计算数组的中位数
np.median(a)
标准差
使用np.std计算标准差
np.std(a)
Python--Pandas
import pandas as pd
1、Pandas是基于NumPy数组构建的,也是Python语言的第三方库,Pandas使数据预处理、清洗、分析工作变得更快更简单,主要用于数据分析。专门为处理表格和混杂数据设计的,相当于Python的Excel,而Numpy更适合处理统一的数组数据。
2、对象
series用于保存一维类的数据,DataFrame用于保存二维类的数据,panel(不常用)用于保存三维类或者可变维度的数据。
3、
3.1创建Dataframe对象
pd.DataFrame(data=None, index=None, columns = None, dtype=None)
data: 可以是嵌套列表,二维数组,字典或者DataFrame对象
index: 可以是索引对象或者类数组对象
跟Series一样,index=None时,则会按照默认的0,1,2...顺序建立索引
columns: 可以是索引对象或者类数组对象,其含义是列索引
字典法创建
data = {"grammer":['Python', 'C', 'Java', 'GO', 'css', 'SQL', 'PHP', 'Python'],
"score":[1.0, 2.0, 6.0, 4.0, 5.0, 6.0, 7.0, 10.0]}
df = pd.DataFrame(data)
df
先创建空的,再加入列
df1 = pd.DataFrame()
df1['ID'] = [0,1,2]
df1
In [ ]:
df1['name'] = ['a','b','c']
df1
3.2DataFrame对象常用基本属性
1.查看数据维度、查看数据形状
dataframe.ndim
dataframe.shape
2.查看数据的行名称
dataframe.index
3.查看数据的列名称
dataframe.columns
4.查看数据的前几行:(n为设置查看几行,默认为5行)
dataframe.head(n)
5.查看数据的后几行:(n为设置查看几行,默认为5行)
dataframe.tail(n)
df.iloc[-5:, :]
6.数据转置
dataframe.T
7.查看数据是否存在空值(可以连用,dataframe.isnull().sum()统计列中含有缺失值的个数,
dataframe.isnull().any().sum()统计含有缺失值的列数)
dataframe.isnull()
8.按照行名称或列名称进行排序:(axis参数:指定排序的数轴;ascending:默认按照升序排序;当设置为False时,按照降序排序)
dataframe.sort_index(axis=1, ascending=False)
9.按照数据值排序:(axis参数指定排序的数轴;by参数指定按照哪一列或行进行排序;ascending参数指定是升序还是降序)
dataframe.sort_values(by='列名, ascending=False, axis=0)
10.对数据直接进行统计分析(查看描述性统计分析)
dataframe.describe()
11.打印DataFrame对象的信息
dataframe.info()
12.查看数据类型
dataframe.dtypes
13.根据数据类型选取特征
dataframe.select_dtypes(include=None, exclude=None)
14.查看列数
方法一:
len(df.columns)
方法二:
df.shape[1]
15.查看某一列共有几种类别
df['grammer'].nunique()
查看某一列每个类别的个数
df['grammer'].value_counts()
4、数据的读取与保存
4.1 读取excel文件
pd.read_excel('./data/xxx.xlsx')
括号内为excel文件路径
4.2 读取csv文件¶
pd.read_csv('./xxx/data1.csv')
4.3将DataFrame保存成csv文件¶
df.to_csv('xxx.csv')
Python--Matplotlib(可视化数据)
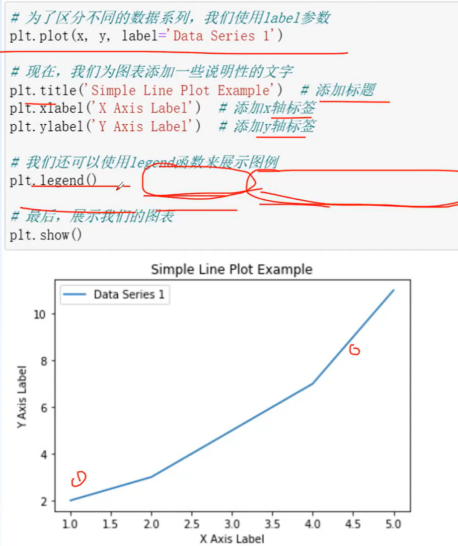
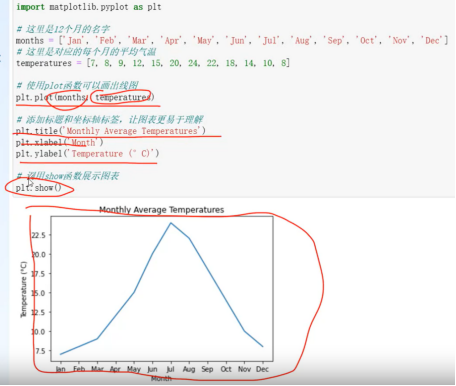
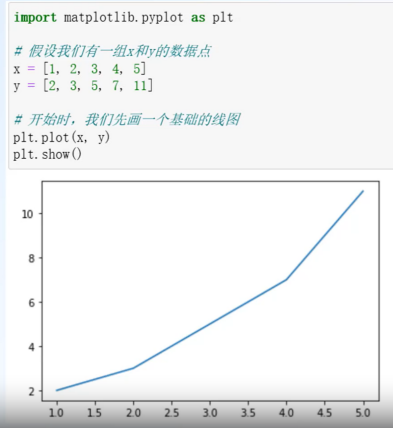
导入相关包:import matplotlib.pyplot as plt
线图:plot()
体现数据变化趋势
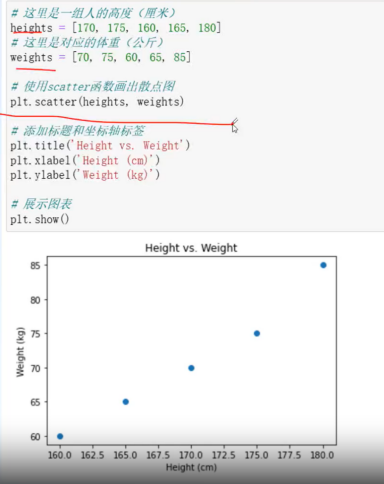
散点图:scatter()
体现数据之间的相关性
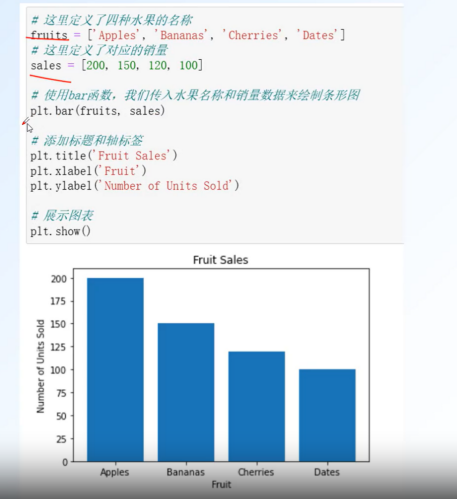
条形图:bar()
体现数据之间的大小
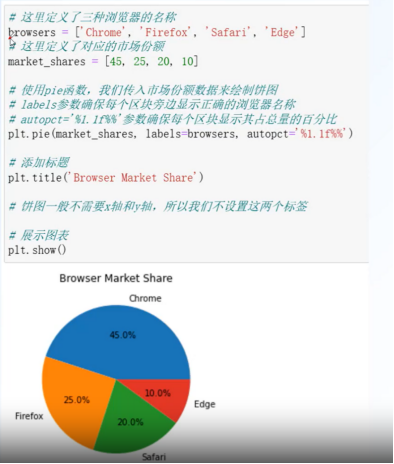
饼图:pie()
体现数据占比
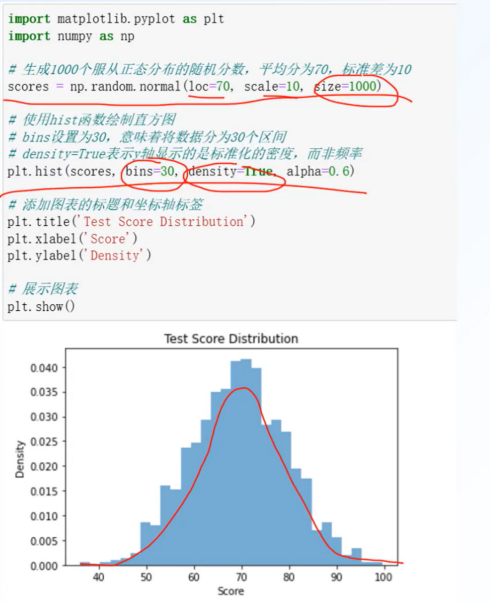
直方图和密度图:hist()
体现数据的分布趋势(正态分布)
多图合并显示:subplot()和subplots() (一张画布多张图)
x:指定x轴数据 y:指定y轴数据
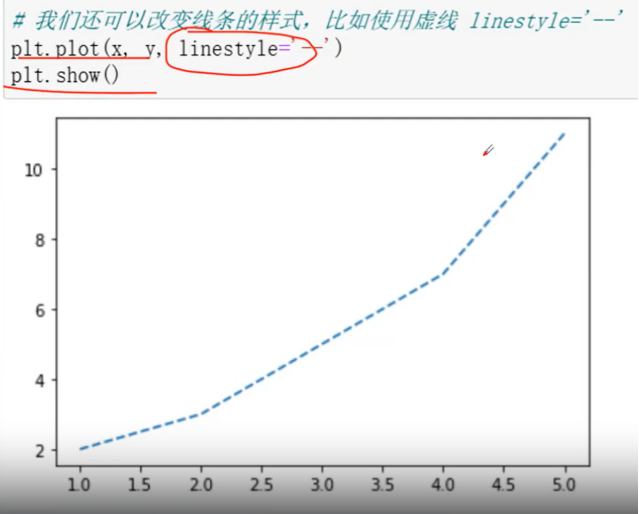
linestyle: 指定折线的类型(实线、虚线、点虚线、点点线……),默认文实线
linewidth: 指定折线的宽度

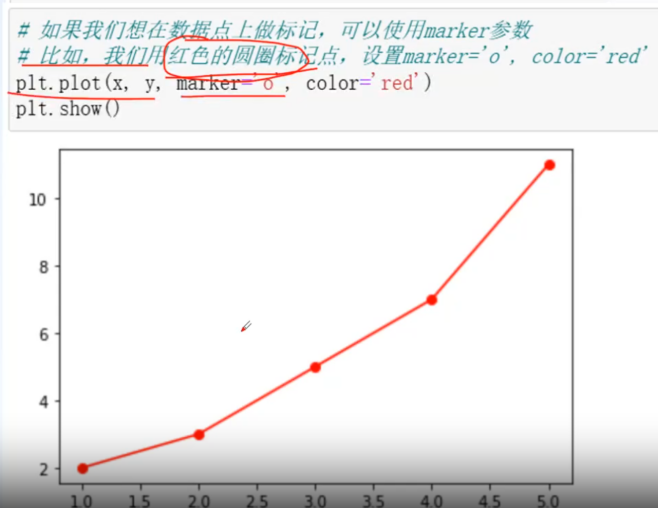
marker:可以为折线图添加点,该参数设置点的形状
markersize:设置点的大小
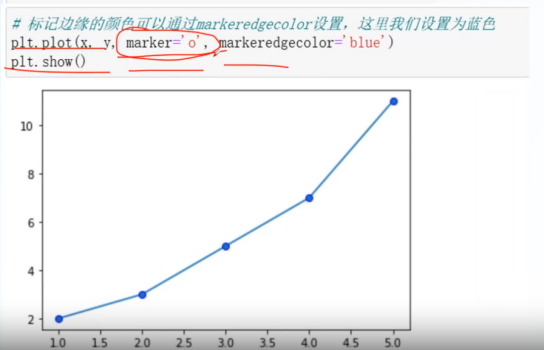
markeredgecolor:设置点的边框色
makerfactcolor:设置点的填充色

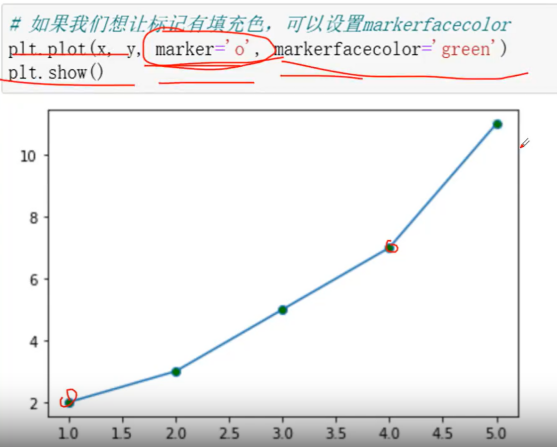
lable:为折线图添加标签,类似于图例的作用