https://gitcode.com/Ascend/pytorch
https://www.hiascend.com/document/detail/zh/Pytorch/710/fastexperience/fastexperience_0001.html
Ascend Extension for PyTorch插件是基于昇腾的深度学习适配框架,使昇腾NPU可以支持PyTorch框架,为PyTorch框架的使用者提供昇腾AI处理器的超强算力。
项目源码地址请参见
昇腾为基于昇腾处理器和软件的行业应用及服务提供全栈AI计算基础设施。您可以通过访问
总体架构
Ascend Extension for PyTorch整体架构如下所示。
图1 Ascend Extension for PyTorch整体架构
放大

-
Ascend Extension for PyTorch(即torch_npu插件):昇腾PyTorch适配插件,继承开源PyTorch特性,针对昇腾AI处理器系列进行深度优化,支持用户基于PyTorch框架实现模型训练和调优。
-
PyTorch原生库/三方库适配:适配支持PyTorch原生库及主流三方库,补齐生态能力,提高昇腾平台易用性。
关键功能特性
-
适配昇腾AI处理器:基于开源PyTorch,适配昇腾AI处理器,提供原生Python接口。
-
框架基础功能:PyTorch动态图、自动微分、Profiling、优化器等。
-
自定义算子开发:支持在PyTorch框架中添加自定义算子。
-
分布式训练:支持原生分布式数据并行训练,包含单机多卡、多机多卡场景支持的集合通信原语,如Broadcast、AllReduce等。
-
模型推理:支持输出标准的ONNX模型可通过离线转换工具将ONNX模型转换为离线推理模型。
absl-py 2.3.1
aclruntime 0.0.2
addict 2.4.0
ais-bench 0.0.2
akg 2.2
albumentations 1.3.1
apex 0.1.dev20240716+ascend
arrow 1.3.0
ascend-training-accuracy-tools 1.0
ascendebug 0.1.0
asgiref 3.8.1
astroid 3.0.3
asttokens 2.4.1
attrs 23.2.0
auto-tune 0.1.0
binaryornot 0.4.4
blinker 1.8.2
blosc2 2.5.1
boto3 1.12.22
botocore 1.15.49
certifi 2024.7.4
cffi 1.16.0
chardet 3.0.4
charset-normalizer 2.0.12
click 8.1.7
click-aliases 1.0.4
cloudpickle 1.3.0
coloredlogs 15.0.1
configparser 6.0.0
contourpy 1.3.0
cookiecutter 2.6.0
coverage 6.4.3
cryptography 3.4.7
cycler 0.12.1
Cython 3.0.2
dask 2.18.1
dataflow 0.0.1
debugpy 1.8.2
decorator 4.4.1
defusedxml 0.8.0rc2
dill 0.3.8
Django 4.2.14
docutils 0.15.2
easydict 1.12
entrypoints 0.4
esdk-obs-python 3.20.1
et-xmlfile 1.1.0
exceptiongroup 1.2.2
executing 2.0.1
filelock 3.15.4
flask 3.0.3
flatbuffers 24.3.25
fonttools 4.53.1
fsspec 2024.6.1
gast 0.6.0
gnureadline 8.1.2
greenlet 3.0.3
grpcio 1.58.0
grpcio-tools 1.58.0
gunicorn 22.0.0
h5py 3.9.0
hccl 0.1.0
hccl-parser 0.1
huaweicloud-sdk-python-modelarts-dataset 0.1.5
huaweicloudsdkcore 3.1.94
humanfriendly 10.0
idna 2.10
ijson 3.3.0
image 1.5.33
imageio 2.34.2
importlib-metadata 8.2.0
importlib-resources 6.5.2
iniconfig 2.0.0
ipykernel 6.7.0
ipython 8.18.1
isort 5.13.2
itsdangerous 2.2.0
jedi 0.19.1
jinja2 3.1.4
jmespath 0.10.0
joblib 1.4.2
jupyter-client 7.4.9
jupyter-core 5.7.2
Keras 2.3.1
Keras-Applications 1.0.8
Keras-Preprocessing 1.1.2
kfac 0.2.0
kiwisolver 1.4.5
lazy-import 0.2.2
lazy-loader 0.4
libclang 18.1.1
libcst 0.4.9
llm-datadist 0.0.1
llm-engine 0.0.1
llvmlite 0.40.1
lxml 4.9.3
ma-cli 1.2.3
ma-mindstudio-insight 1.0.0
ma-tensorboard 1.0.0
markdown 3.8.2
markdown-it-py 3.0.0
MarkupSafe 2.1.5
matplotlib 3.5.1
matplotlib-inline 0.1.7
mccabe 0.7.0
mdurl 0.1.2
mindspore-lite 2.3.0
mindx-elastic 0.0.1
ml-dtypes 0.4.0
mmcv 2.0.1
mmengine 0.10.4
mock 5.1.0
modelarts 1.5.0
modelarts-pytorch-model-server-arm 1.0.6
moxing-framework 2.2.8.0aa484aa
mpi4py 3.1.6
mpmath 1.3.0
msadvisor 1.0.0
msgpack 1.0.8
msit 7.0.0rc630
msit-benchmark 7.0.0rc2
msit-compare 7.0.0rc2
msit-llm 7.0.0rc2
msit-surgeon 7.0.0rc2
msprof-analyze 1.1.2
mypy-extensions 1.0.0
ndindex 1.8
nest-asyncio 1.6.0
networkx 3.2.1
npu-bridge 1.15.0
npu-device 0.1
numba 0.57.1
numexpr 2.8.6
numpy 1.22.0
onnx 1.16.1
onnxconverter-common 1.14.0
onnxruntime 1.15.1
op-compile-tool 0.1.0
op-gen 0.1
op-test-frame 0.1
opc-tool 0.1.0
opencv-python 4.9.0.80
opencv-python-headless 4.10.0.84
openpyxl 3.1.5
packaging 24.1
pandas 1.3.5
parso 0.8.4
pathlib2 2.3.7.post1
pexpect 4.9.0
pillow 10.4.0
pip 21.0.1
platformdirs 4.2.2
pluggy 1.5.0
prettytable 3.10.2
prometheus-client 0.8.0
prompt-toolkit 3.0.47
protobuf 3.20.2
psutil 5.9.5
ptyprocess 0.7.0
pure-eval 0.2.3
py 1.11.0
py-cpuinfo 9.0.0
pyasn1 0.5.1
pycocotools 2.0.7
pycparser 2.22
pycryptodome 3.23.0
pygments 2.18.0
pylint 3.0.2
pyparsing 3.1.2
pypng 0.20220715.0
pytest 7.1.2
python-dateutil 2.9.0.post0
python-slugify 8.0.4
pytz 2024.1
PyWavelets 1.4.1
PyYAML 6.0.1
pyzmq 26.0.3
qudida 0.0.4
requests 2.27.1
requests-toolbelt 1.0.0
rich 13.7.1
s3transfer 0.3.7
schedule-search 0.0.1
scikit-image 0.21.0
scikit-learn 1.5.1
scikit-video 1.1.11
scipy 1.10.1
setuptools 65.5.1
simplejson 3.20.1
six 1.16.0
skl2onnx 1.17.0
SQLAlchemy 2.0.31
sqlparse 0.5.1
stack-data 0.6.3
sympy 1.12.1
tables 3.9.2
tabulate 0.9.0
tailor 0.3.2
tb-graph-ascend 1.0.0
te 0.4.0
tenacity 8.2.2
tensorboard 2.18.0
tensorboard-data-server 0.7.2
tensorflow-probability 0.10.1
termcolor 2.4.0
terminaltables 3.1.0
text-unidecode 1.3
threadpoolctl 3.5.0
tifffile 2024.7.24
toml 0.10.2
tomli 2.0.1
tomlkit 0.13.0
torch 2.1.0
torch-npu 2.1.0.post6.dev20240716
torchvision 0.16.0
tornado 6.4.1
tqdm 4.46.1
traitlets 5.14.3
types-python-dateutil 2.9.0.20250822
typing-extensions 4.12.2
typing-inspect 0.9.0
tzdata 2025.2
umap-learn-modified 0.3.8
urllib3 1.26.7
wcwidth 0.2.13
werkzeug 3.0.3
wheel 0.38.4
xlrd 2.0.1
XlsxWriter 3.2.0
xmltodict 0.13.0
yapf 0.40.2
zipp 3.19.2
# 引入模块
import time
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import torchvision
import torch_npu
from torch_npu.npu import amp # 导入AMP模块
from torch_npu.contrib import transfer_to_npu # 使能自动迁移
# 初始化运行device
device = torch.device('cuda:0')
# 定义模型网络
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.net = nn.Sequential(
# 卷积层
nn.Conv2d(in_channels=1, out_channels=16,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
# 池化层
nn.MaxPool2d(kernel_size=2),
# 卷积层
nn.Conv2d(16, 32, 3, 1, 1),
# 池化层
nn.MaxPool2d(2),
# 将多维输入一维化
nn.Flatten(),
nn.Linear(32*7*7, 16),
# 激活函数
nn.ReLU(),
nn.Linear(16, 10)
)
def forward(self, x):
return self.net(x)
# 下载数据集
train_data = torchvision.datasets.MNIST(
root='mnist',
download=True,
train=True,
transform=torchvision.transforms.ToTensor()
)
# 定义训练相关参数
batch_size = 64
model = CNN().to(device) # 定义模型
train_dataloader = DataLoader(train_data, batch_size=batch_size) # 定义DataLoader
loss_func = nn.CrossEntropyLoss().to(device) # 定义损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=0.1) # 定义优化器
epochs = 10 # 设置循环次数
# 设置循环
for epoch in range(epochs):
print("epoch", epoch)
for imgs, labels in train_dataloader:
start_time = time.time() # 记录训练开始时间
imgs = imgs.to(device) # 把img数据放到指定NPU上
labels = labels.to(device) # 把label数据放到指定NPU上
outputs = model(imgs) # 前向计算
loss = loss_func(outputs, labels) # 损失函数计算
optimizer.zero_grad()
loss.backward() # 损失函数反向计算
optimizer.step() # 更新优化器
# 定义保存模型
torch.save({
'epoch': 10,
'arch': CNN,
'state_dict': model.state_dict(),
'optimizer' : optimizer.state_dict(),
},'checkpoint.pth.tar')
ok完美复现
大模型pytorch MindSpeed-LLM
https://gitcode.com/Ascend/MindSpeed-LLM/wiki/MindSpeed-LLM%E8%BF%81%E7%A7%BB%E6%8C%87%E5%8D%97-Pytorch%E6%A1%86%E6%9E%B6.md
megatron llm 入门资料
https://docs.nvidia.com/megatron-core/developer-guide/latest/user-guide/index.html
https://docs.nvidia.com/megatron-core/developer-guide/latest/api-guide/index.html
https://zhuanlan.zhihu.com/p/650234985
https://zhuanlan.zhihu.com/p/20273101764
🧭 Megatron-LM & MindSpeed-LLM 总结笔记
Ⅰ. Megatron-LM 概述
定义: Megatron-LM 是 NVIDIA 推出的 大规模 Transformer 训练框架,专为上百亿参数模型的分布式训练设计。 它位于 PyTorch 之上,是一种 底层高性能并行引擎,而非模型定义库。
核心特征:
-
支持 3D 并行:Data Parallel + Tensor Parallel + Pipeline Parallel
-
高效显存利用:ZeRO、Activation Recompute
-
通信层基于 NCCL + CUDA
-
混合精度 (FP16/BF16) 与 Fused CUDA Kernels
-
模型适配:GPT、LLaMA、BLOOM、OPT 等
目标: 最大化吞吐与可扩展性,让 Transformer 训练可横跨数百甚至上千 GPU。
Ⅱ. MindSpeed-LLM 概述
定义: MindSpeed-LLM 是华为面向 昇腾 (Ascend) 平台的端到端大模型训练与推理套件, 是 “Megatron-LM 在昇腾硬件上的自研等价体系”。
主要特点:
-
使用 HCCL + ACL 通信与算子库(替代 NCCL + CUDA)
-
集成 MindSpeed 加速库(算子融合、图优化、通信调度)
-
支持预训练、全参微调、LoRA 微调、推理与评估
-
兼容 Hugging Face Transformers 的权重格式,但不依赖其运行逻辑
-
专为 NPU 架构设计的 FP32/16/8 混合精度与内存优化
总结类比:
🧠 Megatron-LM = NVIDIA GPU 平台的训练引擎 ⚙️ MindSpeed-LLM = 昇腾 NPU 平台的训练引擎(架构几乎平行)
Ⅲ. 为什么 MindSpeed-LLM 不直接基于 Transformers
| 角度 | 原因 |
|---|---|
| 算子兼容性 | Transformers 依赖 CUDA/cuDNN,而昇腾用 ACL/HCCL,API 完全不同 |
| 性能优化 | 需要图融合、流水线调度、硬件算子内联,Transformers 层太高 |
| 并行体系 | Megatron 风格 3D 并行 ≠ Transformers 默认的 DDP |
| 生态目标 | 昇腾要构建独立可控 AI 全栈生态,不依赖 CUDA 体系 |
| 战略考虑 | 自研框架可完全掌控性能、版本与国产化路线 |
一句话: Transformers 面向“模型逻辑”;MindSpeed-LLM 面向“硬件执行”。
Ⅳ. Megatron-LM 与 Transformers 的区别与衔接
| 层级 | Transformers | Megatron-LM |
|---|---|---|
| 定位 | 模型定义与接口封装 | 高性能分布式执行框架 |
| 并行方式 | DDP(模型复制) | Tensor + Pipeline 并行(模型分片) |
| 通信粒度 | 同步梯度(反向) | 同步激活/输出(前向) |
| 核心层 | nn.Linear / MultiheadAttention |
ColumnParallelLinear / RowParallelLinear |
| 优化器 | AdamW / Adafactor | FusedAdam / ZeRO 优化 |
| 主要用途 | 推理、小规模微调 | 大规模预训练 |
两者关系:
-
可通过脚本实现 权重互转(Hugging Face ↔ Megatron);
-
常见流程:在 Megatron 训练 → 导出回 Transformers 推理。
Ⅴ. 张量并行(Tensor Parallelism)核心机制
Megatron 将矩阵乘法按张量维度拆分,在多 GPU 共同完成同一层计算。
| 层类型 | 切分维度 | 每卡输出含义 | 合并逻辑 | 通信方式 |
|---|---|---|---|---|
| ColumnParallelLinear | 输出列切分 | 每卡负责部分列 | 拼接 | gather |
| RowParallelLinear | 输入行切分 | 每卡计算部分乘积 | 求和 | all-reduce(sum) |
公式理解:
-
Column 并行: [ W = [W_1 | W_2],\ y_i = x W_i,\ y = [y_1 | y_2] \Rightarrow \text{concatenate} ]
-
![img]()
W = [W_1 | W_2],\ y_i = x W_i,\ y = [y_1 | y_2] \Rightarrow \text{concatenate}
-
Row 并行:
[ W = \begin{bmatrix}W_1 \ W_2\end{bmatrix}, x = [x_1, x_2], y_i = x_i W_i, y = \sum_i y_i \Rightarrow \text{all-reduce(sum)} ]
![img]()
W = \begin{bmatrix}W_1 \ W_2\end{bmatrix}^T, x = [x_1, x_2]^T, y_i = x_i W_i, y = \sum_i y_i \Rightarrow \text{all-reduce(sum)}
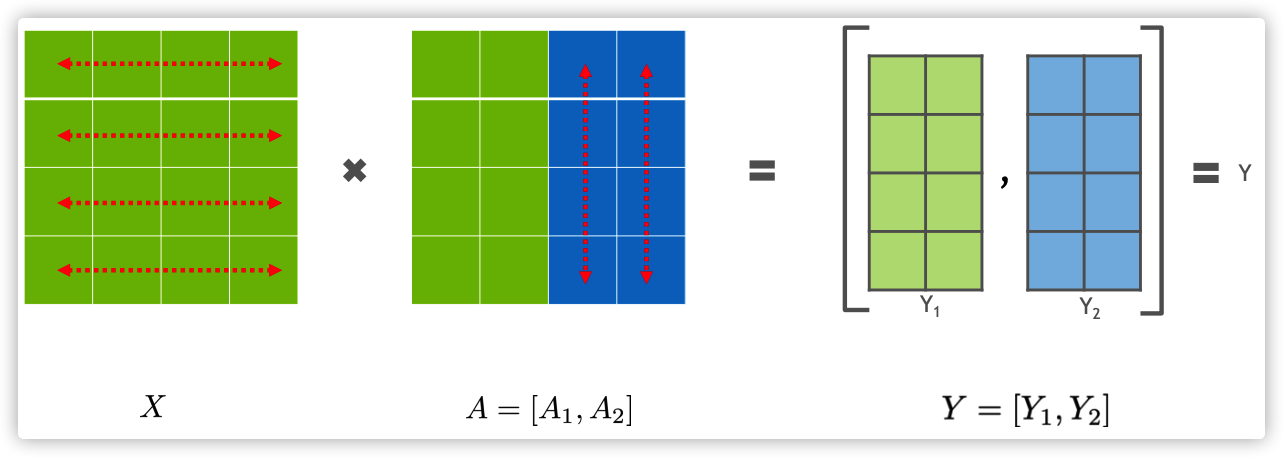
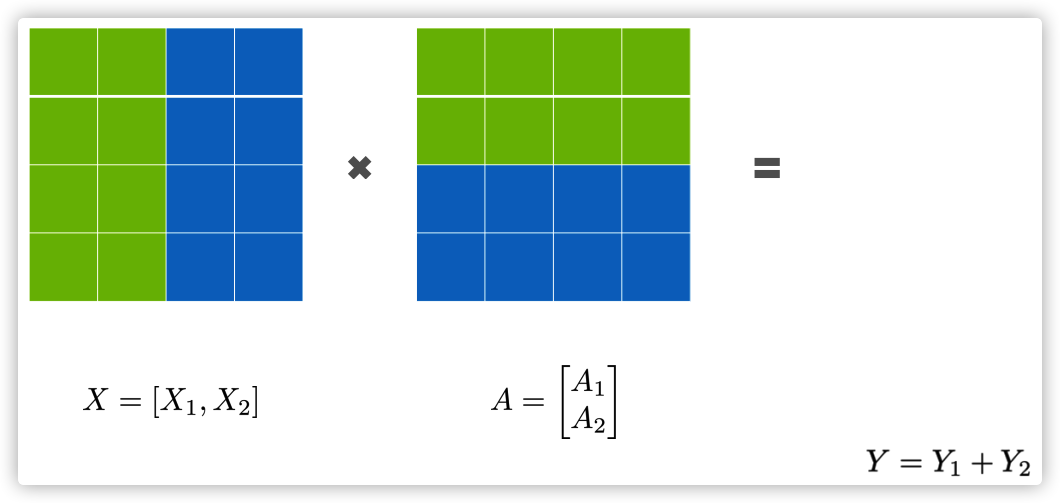
成对使用:
ColumnParallelLinear → GELU → RowParallelLinear
-
前一层分列、后一层分行
-
中间无需通信,只在结尾 all-reduce 一次 → 通信最少、计算完全并行。
CP(Context Parallelism,上下文并行):把序列维度沿长度方向切成多段,分给不同 CP rank。
太可以了!我给你做一个“一批数据如何在 DP / PP / TP / CP 上拆分并协作”的直观小剧场。为了不混淆,我们选一套清晰、不重复的数字:
-
DP=2(两份模型副本)
-
PP=3(三段流水线:S0/S1/S2)
-
TP=2(层内张量并行两片)
-
CP=2(序列/上下文并行两片,等价于把序列沿 tokens 切两半)
-
WORLD_SIZE = 2×3×2×2 = 24 个 rank
-
每步训练的设置:
micro_batch_size=2,梯度累计grad_accum=2⇒ 每个 DP 副本每步吃2×2=4个样本;两份 DP 合起来就是 8 个样本/步 -
模型/输入(仅为演示):
seq_len=8,hidden=12,num_heads=6⇒ TP=2 时每卡 3 个 head;CP=2 时每卡 4 个 token
1) DP:样本怎么分给副本
“数据并行 = 不同模型副本吃不同样本,然后梯度求平均”
-
全局 8 个样本 → 按 DP=2 分成两份:
-
DP 副本 0:样本 #0–#3
-
DP 副本 1:样本 #4–#7
-
-
两个副本完全独立前后向;在反向结束时,只在 DP 组内做一次 grad all-reduce(Megatron 的
LocalDDP会把梯度打包到连续缓冲再 all-reduce,极省通信)。
2) PP:副本内的流水线怎么“流”
“流水线并行 = 模型按层切成 S0/S1/S2,微批次在 stage 间流动(并行)”
每个 DP 副本把自己的 4 个样本再按 grad_accum=2 → 切成 2 个 micro-batch:
-
mb1 = 样本 #0–#1(或 #4–#5)
-
mb2 = 样本 #2–#3(或 #6–#7)
时间线(单个 DP 副本内):
t1: S0 处理 mb1
t2: S0 处理 mb2 | S1 处理 mb1
t3: | S1 处理 mb2 | S2 处理 mb1
t4: | S2 处理 mb2
(反向同理回流)
-
相邻 PP stage 之间用 P2P 传递激活/梯度。
-
若开 虚拟 PP(V-PP),同一张卡的 S0 会再分成 S0a/S0b 交错跑,泡更小(你前面已经掌握了)。
3) TP:层内计算怎么分
“张量并行 = 把同一层的权重/计算切成两片在两张卡上算”
以 Self-Attention 举例(在任一 stage 内):
-
Q/K/V 投影用
ColumnParallelLinear:按列切 → 每个 TP 卡拿到 一半 head(这里每卡 3 个 head),各自本地算注意力 不通信; -
输出投影 out_proj用
RowParallelLinear:按行切 → 计算后需要一次 all-reduce(sum) 聚合成完整输出; -
MLP 的两个线性层也分别按列/行切,通信点与上面同理。
直觉:TP=2 = “把 head/hidden 切两半”,注意力本体不需要通信,只在输出投影(以及 RowParallel 的地方)做一次 all-reduce。
4) CP(或 Sequence/Context Parallel):序列怎么切
“序列并行/上下文并行 = 把同一个样本的 tokens 沿序列维切给多卡”
-
CP=2 时,
seq_len=8→ 每卡 4 个 token(如 tokens 0–3 和 4–7)。 -
某些算子(LayerNorm、残差加)只需要局部 token 信息 → 纯本地;
-
Attention 需要全序列的 K/V(或注意力得分):
-
方案 A(简化理解):先 all-gather K/V 到每个 CP 卡,再本地做
QK^T和乘V;反传时 reduce-scatter 回各自 token 切片; -
方案 B(更高效的环形/分块实现):Megatron-CP 用更细的环通信把
QK^T/AV分步完成,峰值显存更低。
-
-
后续 MLP 的 激活/梯度 也在 CP 组内按 token 进行对齐的 gather/scatter。
直觉:CP=2 = “把序列一分为二”,需要的地方按需全量化/还原,常见模式是 all-gather(前向)+ reduce-scatter(反向)。
5) 把三维(TP×CP)放进一个 stage 的“棋盘格”
在任意 PP stage 上,一张 GPU 实际承接的是一个 (tp, cp) 二维坐标里的那一小块:
TP shard 0 TP shard 1 (→ 切 head/hidden)
CP 0 ┌───────────────┬───────────────┐
(上) │ tokens 0..3 │ tokens 0..3 │
│ heads 0..2 │ heads 3..5 │
└───────────────┴───────────────┘
CP 1 ┌───────────────┬───────────────┐
(下) │ tokens 4..7 │ tokens 4..7 │
│ heads 0..2 │ heads 3..5 │
└───────────────┴───────────────┘
(↑ 切序列/token)
-
横向(TP):分 head/hidden,主要在
RowParallelLinear处 all-reduce; -
纵向(CP):分 token,注意力/某些层需要 all-gather / reduce-scatter;
-
对角(不同 (tp,cp) 块):互相独立,各算各的。
6) “一批数据”的全链路协作(从喂样本到更新)
把 8 个样本的一次训练步串起来看(省略 V-PP):
-
DP 切样本:
-
DP0:#0–#3 → mb1(#0–#1), mb2(#2–#3)
-
DP1:#4–#7 → mb1(#4–#5), mb2(#6–#7)
-
-
PP 流动(每个 DP 内部):
-
t1:S0 处理 mb1
-
t2:S0 处理 mb2,S1 处理 mb1
-
t3:S1 处理 mb2,S2 处理 mb1
-
t4:S2 处理 mb2(随后反向回流)
-
-
每个 PP stage 内(算一次前向的某层):
-
TP:QKV 列切(本地),Attention 本地,out_proj 行切 + all-reduce;
-
CP:token 切分;Attention 处按需 all-gather K/V(或环式通信),反向 reduce-scatter。
-
-
反向完成后:
-
先在 TP / CP 组内完成各自需要的还原/规约;
-
再在 DP 组内对已聚合好的连续梯度缓冲做 all-reduce(一次/每 dtype 一次);
-
优化器 step 更新参数;若用分布式优化器再触发参数 all-gather。
-
通信频率/对象(记住这个清单就不乱)
PP:相邻 stage 之间 P2P(激活/梯度)
TP:主要在
RowParallelLinear/ MLP 第二层处 all-reduceCP:注意力/某些层 all-gather(前) + reduce-scatter(后)
DP:一次梯度 all-reduce(Megatron-LocalDDP 把它做得很省)
7) 小而全的映射例子(只列出一个 DP 副本的一条流水线)
以 DP=0 的一条流水线为例,列几个典型 rank 的四元坐标 (dp, pp, tp, cp):
S0: (0,0,0,0) (0,0,1,0)
(0,0,0,1) (0,0,1,1)
S1: (0,1,0,0) (0,1,1,0)
(0,1,0,1) (0,1,1,1)
S2: (0,2,0,0) (0,2,1,0)
(0,2,0,1) (0,2,1,1)
-
每个 PP stage 有 TP×CP=2×2=4 个 rank(共 12 个 rank 属于 DP=0 的完整模型副本)。
-
DP=1 这套再来一遍(全局 rank 偏移一个
TP×PP×CP = 12的块)。
结论(背下来就会用)
-
DP:分样本,只在反向末尾 all-reduce 梯度。
-
PP:分层/分段,相邻段 P2P 串起来。
-
TP:分 head/hidden,注意力本体局部、输出投影 all-reduce。
-
CP(序列并行):分 token,注意力处 all-gather / reduce-scatter。
它们是正交的维度:同一条样本在 PP 上流动;在每个 stage 内被 TP×CP 切片各自算;最后在 DP 上把梯度汇总更新。 这样就能把大模型+长序列+大 batch同时“塞满”多卡、又把通信控制在必要的点上。
Ⅵ. tensor_model_parallel_all_reduce 内部原理
作用:
在同一 tensor-parallel 组内,将所有 GPU 的部分输出 求和并同步, 确保每张卡都拥有逻辑上完整的输出张量。
简化代码:
def tensor_model_parallel_all_reduce(tensor):
group = get_tensor_model_parallel_group()
torch.distributed.all_reduce(tensor, group=group)
return tensor
通信过程(ring all-reduce):
GPU0: y0 ─┐
GPU1: y1 ├─→ all-reduce(sum) → [y0+y1+...]
GPU2: y2 ├─→ 每卡获得完整结果
GPU3: y3 ─┘
区别于 DDP:
| 维度 | DDP | Megatron |
|---|---|---|
| 同步时机 | 反向阶段(梯度) | 前向阶段(激活) |
| 并行粒度 | 模型级复制 | 层内张量级切分 |
| 通信内容 | gradients | partial outputs |
| 目的 | 各模型参数一致 | 各张量输出一致 |
##
Transformers: 定义 Transformer 的“逻辑结构” Megatron-LM: 定义 Transformer 在多 GPU 上“如何执行” MindSpeed-LLM: Megatron-LM 的昇腾版本,替换底层通信与算子栈。
张量并行核心哲学:
列切分 → 拼接 (gather)
行切分 → 求和 (all-reduce)
这样既保证数学等价性,又实现高效分布式训练。
https://gitcode.com/Ascend/MindSpeed-LLM/blob/2.1.0/docs/quick_start.md
尝试qwen3-1.7B训练
坑点1
unable to load loader plugin qwen_hf. Exiting.
重新按照脚本重装环境,要按照docs/pytorch/install_guide.md来
坑点2
building GPT model ...
INFO:root:received transformer layer 21
INFO:root:received transformer layer 22
INFO:root:received transformer layer 23
ERROR:root:Unexpected message. Expecting "final norm" but got "transformer layer 24". Exiting saver.
ERROR:root:saver process exited with error code 1
/home/ma-user/anaconda3/envs/PyTorch-2.1.0/lib/python3.9/tempfile.py:821: ResourceWarning: Implicitly cleaning up <TemporaryDirectory '/tmp/tmpvdz0g6ec'>
_warnings.warn(warn_message, ResourceWarning)
检查原因是:
# 要保证--target-pipeline-parallel-size 8 能被整除! 一张卡直接设置成1
python convert_ckpt.py \
--use-mcore-models \
--model-type GPT \
--load-model-type hf \
--save-model-type mg \
--target-tensor-parallel-size 1 \
--target-pipeline-parallel-size 8 \
--spec mindspeed_llm.tasks.models.spec.qwen3_spec layer_spec \
--load-dir ./model_from_hf/qwen3_hf/ \
--save-dir ./model_weights/qwen3_mcore/ \
--tokenizer-model ./model_from_hf/qwen3_hf/tokenizer.json \
--params-dtype bf16 \
--model-type-hf qwen3
看config.json "max_window_layers": 28,
{
"architectures": [
"Qwen3ForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 151643,
"eos_token_id": 151645,
"head_dim": 128,
"hidden_act": "silu",
"hidden_size": 2048,
"initializer_range": 0.02,
"intermediate_size": 6144,
"max_position_embeddings": 40960,
"max_window_layers": 28,
"model_type": "qwen3",
"num_attention_heads": 16,
"num_hidden_layers": 28,
"num_key_value_heads": 8,
"rms_norm_eps": 1e-06,
"rope_scaling": null,
"rope_theta": 1000000,
"sliding_window": null,
"tie_word_embeddings": true,
"torch_dtype": "bfloat16",
"transformers_version": "4.51.0",
"use_cache": true,
"use_sliding_window": false,
"vocab_size": 151936
}
坑点3
注意设备数 = TP × PP × DP × CP
-
如果转换时设了
--target-pipeline-parallel-size 4, 那训练时也必须PP=4(且至少 4 张 NPU)。 -
单卡调试必须转换时
PP=1、训练时也PP=1。 -
否则加载器会在错误的 rank 目录下查找权重。
总结如何修改脚本适配运行
一、核心一致性原则
1️⃣ 并行一致(Parallel Consistency)
设备数 = TP × PP × DP × CP
-
如果转换时设了
--target-pipeline-parallel-size 4, 那训练时也必须PP=4(且至少 4 张 NPU)。 -
单卡调试必须转换时
PP=1、训练时也PP=1。 -
否则加载器会在错误的 rank 目录下查找权重。
一、全局 rank 到三维坐标的映射
把每个全局 rank r 映射到三维索引 (dp, pp, tp):
-
先算:
rep = TP * PP = 3 * 4 = 12(单个模型副本占的进程数) -
\textbf{dp} = r // rep
-
offset = r % rep -
\textbf{pp} = offset // TP
-
\textbf{tp} = offset % TP
反向(从 (dp,pp,tp) 得到全局 rank):
r = dp \times (TP\times PP) \;+\; pp \times TP \;+\; tp.
$$
记忆口诀:tp 最快变,pp 次之,dp 最慢。
当然,这里给你一个整齐一行展示的例子,直观地看出 rank 与三维坐标 (dp, pp, tp) 的映射关系。
我们还是用上面的设置: WORLD_SIZE=24, TP=3, PP=4, DP=2
✅ 一行直观展示
| rank | (dp, pp, tp) |
|---|---|
| 0 | (0,0,0) |
| 1 | (0,0,1) |
| 2 | (0,0,2) |
| 3 | (0,1,0) |
| 4 | (0,1,1) |
| 5 | (0,1,2) |
| 6 | (0,2,0) |
| 7 | (0,2,1) |
| 8 | (0,2,2) |
| 9 | (0,3,0) |
| 10 | (0,3,1) |
| 11 | (0,3,2) |
| 12 | (1,0,0) |
| 13 | (1,0,1) |
| 14 | (1,0,2) |
| 15 | (1,1,0) |
| 16 | (1,1,1) |
| 17 | (1,1,2) |
| 18 | (1,2,0) |
| 19 | (1,2,1) |
| 20 | (1,2,2) |
| 21 | (1,3,0) |
| 22 | (1,3,1) |
| 23 | (1,3,2) |
💡 规律总结:
-
tp每 +1 → rank +1(最内层循环) -
pp每 +1 → rank +TP(跨一个张量并行块) -
dp每 +1 → rank +TP×PP(跨一个完整模型副本)
也就是:
tp 变化最快 → rank 连续
pp 次快 → 每 3 个 rank 换一组
dp 最慢 → 每 12 个 rank 换一组
虚拟 PP = 在不增加 GPU 数量的前提下,把流水线再细分,从而打破“PP 并行度必须等于可用 GPU 数”的限制。
| 实际设备数 | 合法配置 |
|---|---|
| 单卡 | TP=1, PP=1, DP=1, CP=1 |
| 4 卡流水线 | TP=1, PP=4, DP=1, CP=1 |
| 8 卡张量+流水混合 | TP=2, PP=4, DP=1, CP=1 |
2️⃣ 结构一致(Structural Consistency)
训练脚本参数与 HuggingFace 的
config.json完全一致
| 参数 | HF config 值 | 脚本中应设置 |
|---|---|---|
num_hidden_layers |
28 | --num-layers 28 |
hidden_size |
2048 | --hidden-size 2048 |
intermediate_size |
6144 | --ffn-hidden-size 6144 |
num_attention_heads |
16 | --num-attention-heads 16 |
num_key_value_heads |
8 | --num-query-groups 8 |
rope_theta |
1000000 | --rotary-base 1000000 |
rms_norm_eps |
1e-6 | --norm-epsilon 1e-6 |
vocab_size |
151936 | --padded-vocab-size 151936 |
⚠️ 如果 mismatch(如 head 数或 ffn_hidden_size 不对),加载时报 shape mismatch 或 key error。
📦 二、HuggingFace 配置文件(config.json)
{
"architectures": ["Qwen3ForCausalLM"],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 151643,
"eos_token_id": 151645,
"head_dim": 128,
"hidden_act": "silu",
"hidden_size": 2048,
"initializer_range": 0.02,
"intermediate_size": 6144,
"max_position_embeddings": 40960,
"max_window_layers": 28,
"model_type": "qwen3",
"num_attention_heads": 16,
"num_hidden_layers": 28,
"num_key_value_heads": 8,
"rms_norm_eps": 1e-06,
"rope_theta": 1000000,
"vocab_size": 151936,
"torch_dtype": "bfloat16"
}
🔁 三、模型转换脚本(HF → MindSpeed 格式)
# 激活 Ascend 工具环境
export CUDA_DEVICE_MAX_CONNECTIONS=1
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# 模型转换:HF -> MindSpeed (mcore)
python convert_ckpt.py \
--use-mcore-models \
--model-type GPT \
--load-model-type hf \
--save-model-type mg \
--target-tensor-parallel-size 1 \
--target-pipeline-parallel-size 4 \
--spec mindspeed_llm.tasks.models.spec.qwen3_spec layer_spec \
--load-dir ./model_from_hf/qwen3_hf/ \
--save-dir ./model_weights/qwen3_mcore/ \
--tokenizer-model ./model_from_hf/qwen3_hf/tokenizer.json \
--params-dtype bf16 \
--model-type-hf qwen3
✅ 转换输出结构说明
当你设 PP=4 时,28 层模型会被均分成 4 段(每段 7 层):
model_weights/qwen3_mcore/
iter_0000001/
mp_rank_00_000/ ← stage0,7 层
mp_rank_00_001/ ← stage1,7 层
mp_rank_00_002/ ← stage2,7 层
mp_rank_00_003/ ← stage3,7 层
训练时若 PP=1 就加载失败;必须 PP=4 并有 4 张 NPU 对应。
四、训练脚本(可直接运行)