随着数字化转型的深入,档案管理正从传统的实体保管向数字化、智能化的知识服务转变。在这一变革中,文档抽取技术作为自然语言处理和人工智能的关键分支,正扮演着愈发重要的角色。本文将深入探讨文档抽取技术如何重塑现代档案管理系统,使其从“信息的仓库”升级为“知识的引擎”。
档案管理面临的挑战与机遇
传统的档案管理系统主要解决档案的“存”与“管”的问题,即安全存储、规范编目和权限控制。然而,面对海量、多格式(如扫描图片、PDF、Word、电子邮件)的档案资源,系统面临着严峻挑战:
- 信息沉睡:大量非结构化文档中的关键信息(如人名、地点、金额、条款)无法被直接检索和利用,成为“数据坟墓”。
- 编目效率低下:依赖人工阅读、提取关键词和编制元数据,耗时耗力,且容易出错和不一致。
- 检索体验不佳:用户只能通过有限的标题、日期等字段进行模糊检索,难以精准定位到文档内的具体内容。
- 知识挖掘困难:难以从海量档案中发现隐藏的关联、趋势和模式,无法为决策提供深层支持。
文档抽取技术正是破解这些难题的“金钥匙”。它能够自动从非结构化或半结构化文档中识别并提取出预定义的、有意义的信息,并将其转化为结构化数据,从而释放档案数据的巨大价值。
文档抽取技术简介
文档抽取技术主要包含以下几个核心能力:
- 光学字符识别:将扫描版文档、图片中的文字转换为机器可读、可处理的文本。
- 实体识别:从文本中识别并分类出命名实体,如人名、组织机构、地点、时间、专有名词等。
- 关键信息抽取:定位并提取文档中特定的关键信息,如合同中的“甲方”、“乙方”、“金额”、“签署日期”;发票中的“税号”、“商品名称”、“总价”等。
- 关系抽取:识别不同实体或信息之间的语义关系,例如“某人与某公司存在雇佣关系”、“某项目由某部门负责”。
- 分类与聚类:根据文档内容自动进行主题分类或将其归入已有的档案分类体系。
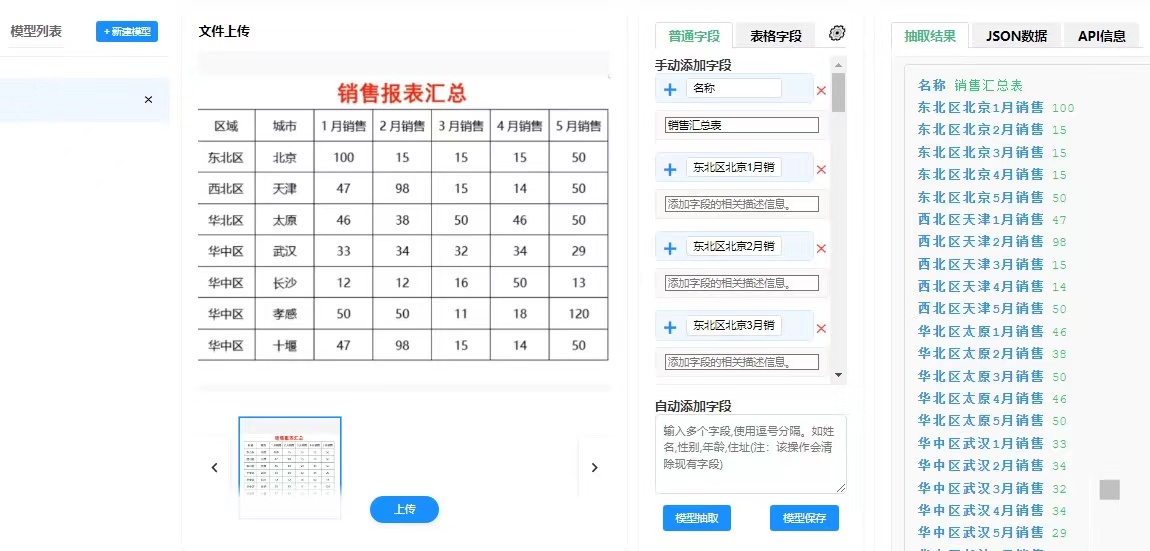
文档抽取技术在档案管理系统中的核心作用
1. 实现档案元数据的自动化、精准化著录
作用:传统元数据著录(如题名、责任者、日期、主题词等)高度依赖人工。文档抽取技术可以自动从文档正文、标题页、公章等处提取这些信息,并自动填入元数据字段。
价值:
- 大幅提升效率:将馆员从重复、繁琐的著录工作中解放出来,处理速度提升数十倍。
- 保证准确性与一致性:减少人为错误和主观判断差异,确保元数据标准统一。
- 支持批量处理:快速完成历史存量档案的数字化回溯与数据初始化。
2. 打造深度化、智能化的档案检索体验
作用:通过实体识别和关键信息抽取,系统不仅对档案标题进行索引,更对文档全文中的每一个关键信息点建立索引。
价值:
- 实现“内容级”精准检索:用户可以直接搜索“与XX公司于2023年签署的合同”,或“所有包含张三批示的文件”,系统能直接定位到相关文档甚至具体段落。
- 支持语义检索与知识问答:结合知识图谱技术,系统可以回答更复杂的问题,如“张三在A项目期间主要负责了哪些工作?”
3. 赋能档案内容的深度挖掘与知识发现
作用:通过对海量档案进行实体、关系和主题的批量抽取,系统能够构建出档案资源的知识图谱。
价值:
- 揭示关联关系:可视化地展示人物、事件、机构之间的复杂网络,帮助研究人员发现隐藏的历史联系或业务逻辑。
- 趋势分析:分析特定主题(如“某项政策”)在历年档案中出现的频率和演变,辅助宏观决策。
- 智能推送与推荐:当用户查阅一份档案时,系统可自动推荐与之相关的人物、事件或其他档案,拓展研究视野。
4. 优化档案业务流程与服务工作
作用:在归档、鉴定、利用等环节提供智能辅助。
价值:
- 智能归档:自动根据文档内容判断其所属的档案门类和保管期限。
- 高效查档服务:在民生档案查询(如婚姻、房产、工龄证明)中,快速定位所需信息,极大缩短群众等待时间。
- 专题汇编:快速从海量档案中抽取与某一特定主题(如“重大工程”、“重要会议”)相关的所有文档,自动生成专题汇编素材。
文档抽取技术是驱动档案管理系统迈向“智慧档案”的核心引擎。它通过将非结构化信息转化为可计算、可关联的结构化知识,彻底改变了档案的著录、检索、分析和利用模式。对于各类档案馆、企事业单位而言,积极拥抱并应用这一技术,不仅是提升管理效率的必然选择,更是盘活档案数据资产、挖掘历史价值、赋能未来决策的战略举措。档案,因此不再是尘封的故纸堆,而是奔流不息的知识之源。