作业1
目录
- 作业1
- 作业①
- 1)代码与结果
- 2)心得体会
- 作业②
- 1)代码与结果
- 2)心得体会
- 作业③
- 1)代码与结果
- 2)心得体会
gitee仓库
· https://gitee.com/jh2680513769/2025_crawler_project
作业①
1)代码与结果
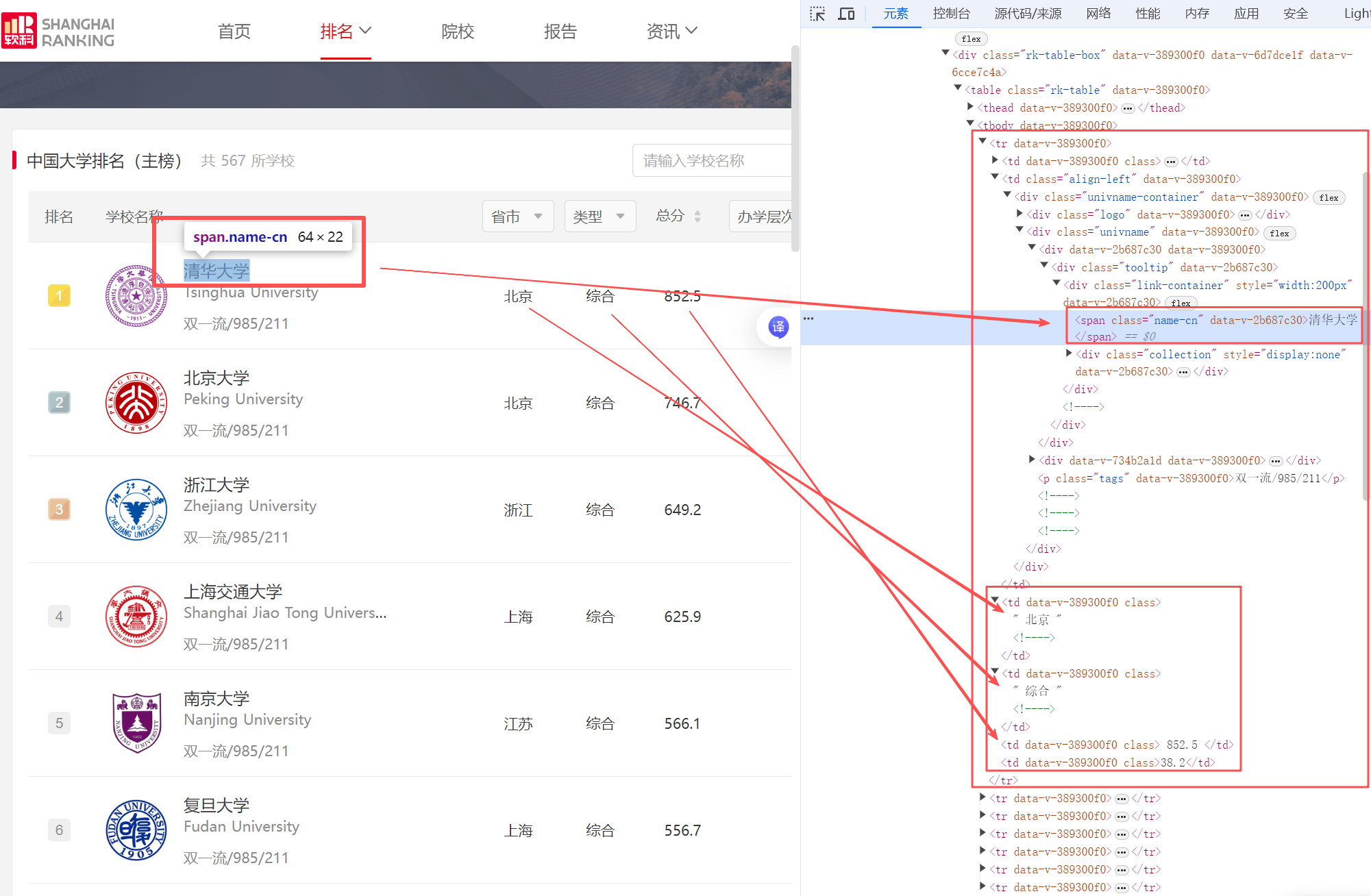
首先打开给定网页 2020中国大学排名 ,F12查看HTML元素。通过查找,发现信息都存放在class属性值为rk-table的<table>元素里。在此基础上编写程序逐一提取表格行及有效信息,最后输出排名信息。
网页信息
核心代码
import requests
from bs4 import BeautifulSoup
#访问网页、获取网页标签
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
resp = requests.get(url)
resp.encoding='utf-8'
html = resp.text
print(f"{'排名':^8}{'学校名称':^12}{'省市':^8}{'学校类型':^8}{'总分':^10}")
#解析网页
soup = BeautifulSoup(html, 'html.parser')
#查找表格行元素
table = soup.find('table', {'class':'rk-table'})
datas = []
rows = table.find('tbody').find_all('tr')
#析取有效信息
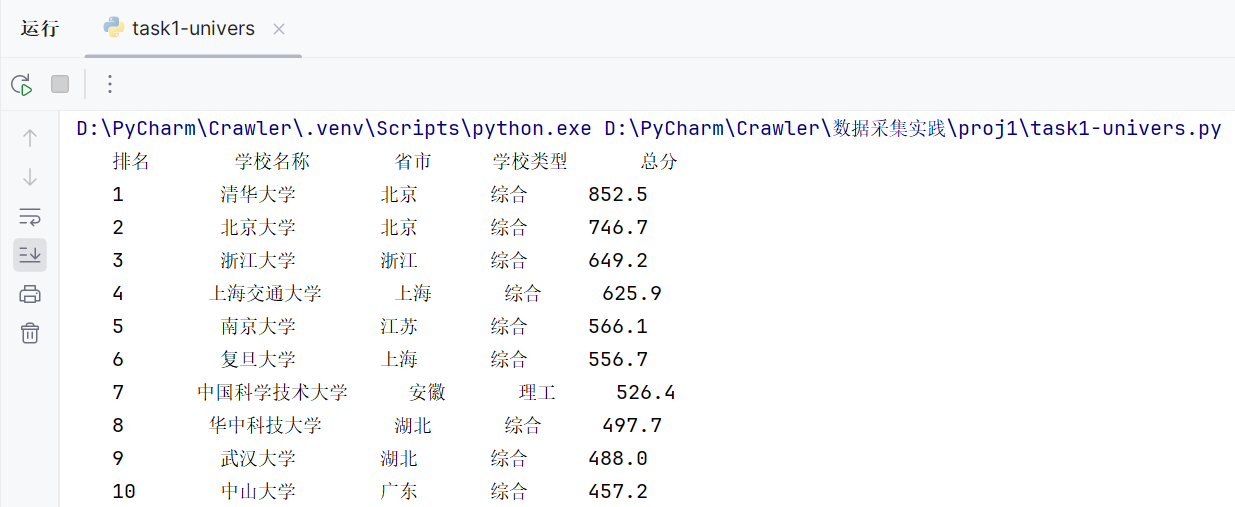
for row in rows:cells = row.find_all('td')rank = cells[0].get_text().strip()name = cells[1].find('span').get_text().strip()province = cells[2].get_text().strip()school_type = cells[3].get_text().strip()score = cells[4].get_text().strip()print(f"{rank:^8}{name:^12}{province:^8}{school_type:^8}{score:^10}")
运行结果
2)心得体会
用BeautifulSoup库解析网页可以直接提取所需元素,个人觉得比使用re库找元素更高效。原本想试着分页爬取,让大模型分析之后,发现这个网页分页机制使用了Ant Design的ant-pagination类,可以用Selenium来应对,因为还没学习这部分内容,就没有继续探究了。
作业②
1)代码与结果
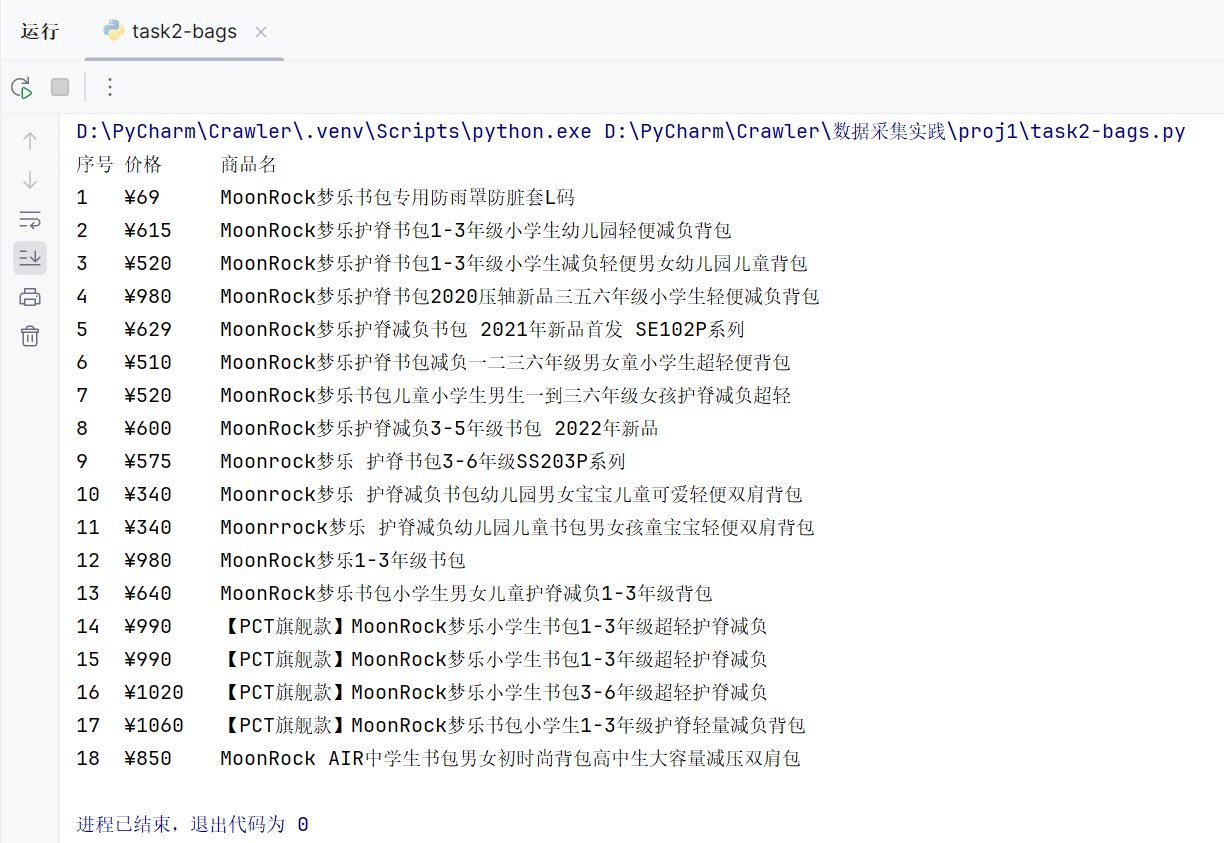
这个任务首先找了一个小商城网页搜索关键词“书包”- MoonRock梦乐官方商城 。和上题步骤类似,先在网页的HTML中定位到各个商品的价格和名称信息,剩下任务主要是编写正则表达式。
网页信息

核心代码
import requests
import re
#访问网页获取网页标签
url = 'https://moonrockbags.cn/search.php?encode=YToyOntzOjg6ImtleXdvcmRzIjtzOjY6IuS5puWMhSI7czoxODoic2VhcmNoX2VuY29kZV90aW1lIjtpOjE3NjEyNzA3NjM7fQ=='
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 SLBrowser/9.0.6.8151 SLBChan/111 SLBVPV/64-bit'
}
resp = requests.get(url, headers=headers)
resp.encoding = 'utf-8'
html = resp.text
#正则表达式析取网页信息
items = re.findall(r'<li id="li_\d{4}" class="(item|item last)">(.*?)</li>', html, re.S)
print(f"序号\t{'价格':6}\t商品名")
for i in range(len(items)):name = re.findall(r'<div class="item-name">.*?<a href=".*" target="_blank" title="([^"]*)"', items[i][1], re.S)[0]price = re.findall(r'<em class="sale-price main-color"[^>]*>(.*?)</em>', items[i][1], re.S)[0]print(f"{i+1}\t{price:6}\t{name}")
运行结果
2)心得体会
相比于使用bs4库,我认为用re库析取信息是最直接的,但缺点是正则表达式编写比较麻烦容易出错,写代码过程中要经常检查提取的信息是否有误或多余。然后也是尝试分页爬取,依旧动态分页,凭己浅薄之力暂时无法解决,等学完后面知识再来试试吧。
作业③
1)代码与结果
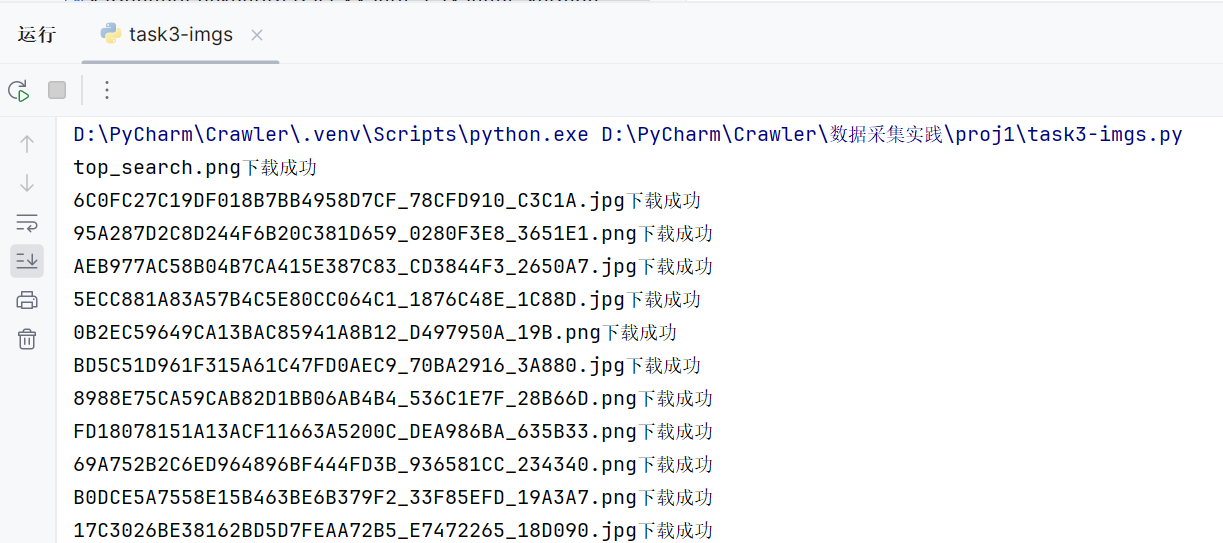
任务目标是爬取 福州大学新闻网-影像福大 的所有JPEG、JPG、PNG格式文件并保存在同一文件夹下。没有规定特定使用的库,我这里就优先考虑用BeautifulSoup了,毕竟更容易上手,而且可以直接找到<img>元素的特定属性src。没用re库可能是为了节约时间。
网页信息

核心代码
import requests
from bs4 import BeautifulSoup
import os
from urllib.parse import urljoin #处理url拼接
urls = ['https://news.fzu.edu.cn/yxfd.htm', 'https://news.fzu.edu.cn/yxfd/5.htm', 'https://news.fzu.edu.cn/yxfd/4.htm','https://news.fzu.edu.cn/yxfd/3.htm', 'https://news.fzu.edu.cn/yxfd/2.htm', 'https://news.fzu.edu.cn/yxfd/1.htm'
]
img_urls = []
for url in urls:#发送请求resp = requests.get(url)resp.encoding = 'utf-8'html = resp.text#解析网页soup = BeautifulSoup(html, 'html.parser')for img in soup.find_all('img'):src = img.get('src')if src.lower().endswith(('.jpg', '.png', '.jpeg')):#提取图片属性,拼接urlfull_url = urljoin(url, src)img_urls.append(full_url)
#去掉重复的图片
img_urls = list(set(img_urls))
#创建文件夹,下载保存图片文件
folder_name = "download_images"
if not os.path.exists(folder_name):os.makedirs(folder_name)
for img_url in img_urls:try:img_resp = requests.get(img_url)if img_resp.status_code == 200:img_name = os.path.basename(img_url)#处理文件名非法字符if '?' in img_name:img_name = img_name.split('?')[0]filepath = os.path.join(folder_name, img_name)with open(filepath, 'wb') as f:f.write(img_resp.content)print(f"{img_name}下载成功")except Exception as e:print(e)
运行结果
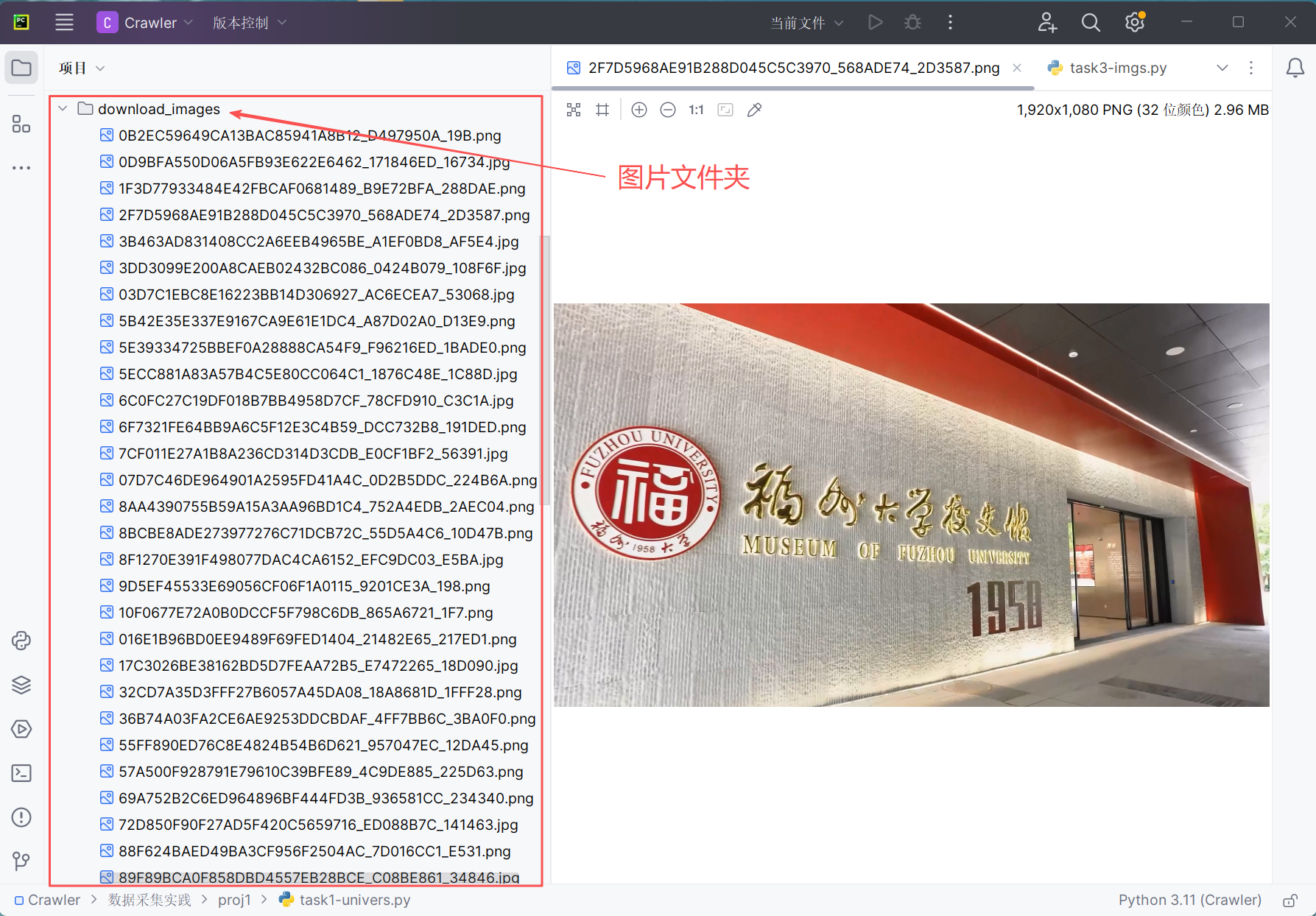
2)心得体会
前面对网页的访问、解析、查找信息等步骤基本不变,调用urljoin处理url拼接。另外,关注到分页设计都是固定的url(静态网页),于是用列表设计爬取所有的网页图片。下载图片时反复报错,最后发现是由于直接从url中提取图片名所致,还需进一步处理非法字符才能作为文件名顺利下载保存在文件夹中。