目录
- 作业一
- 实验过程及结果-1
- 心得体会-1
- 作业二
- 实验过程及结果-2
- 心得体会-2
- 作业三
- 实验过程及结果-3
- 心得体会-3
作业一:
实验过程及结果-1
- 要想爬取到网站中大学的信息,应当先查看该网站中html的结构,通过搜索框搜索<table标签,观察表结构,构建标签树
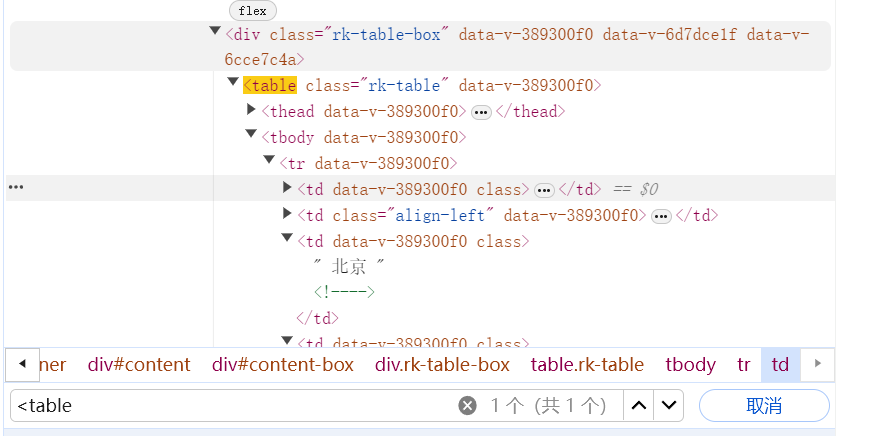
- 明确了标签树的结构后,就可以开始写代码了,目前我们学习了requests和BeautifulSoup库,数据获取阶段使用request方法获取到网页的html文本内容,之后使用BeautifulSoup解析HTML,由标签树可知tr为表格行,可以遍历每一行tr,找到对应的td元素,按顺序打印出来即可
- 完整代码
点击查看代码
import requests
from bs4 import BeautifulSoup#数据获取阶段
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
response = requests.get(url)
response.encoding = 'utf-8'
html = response.text
#HTML解析阶段
soup = BeautifulSoup(html, 'html.parser')
table = soup.find('table', class_='rk-table')tbody = table.find('tbody')
trs = tbody.find_all('tr')
# 对齐的表头
print("{:<4} {:<16} {:<6} {:<8} {:<8}".format("排名", "学校名称", "省市", "学校类型", "总分"))
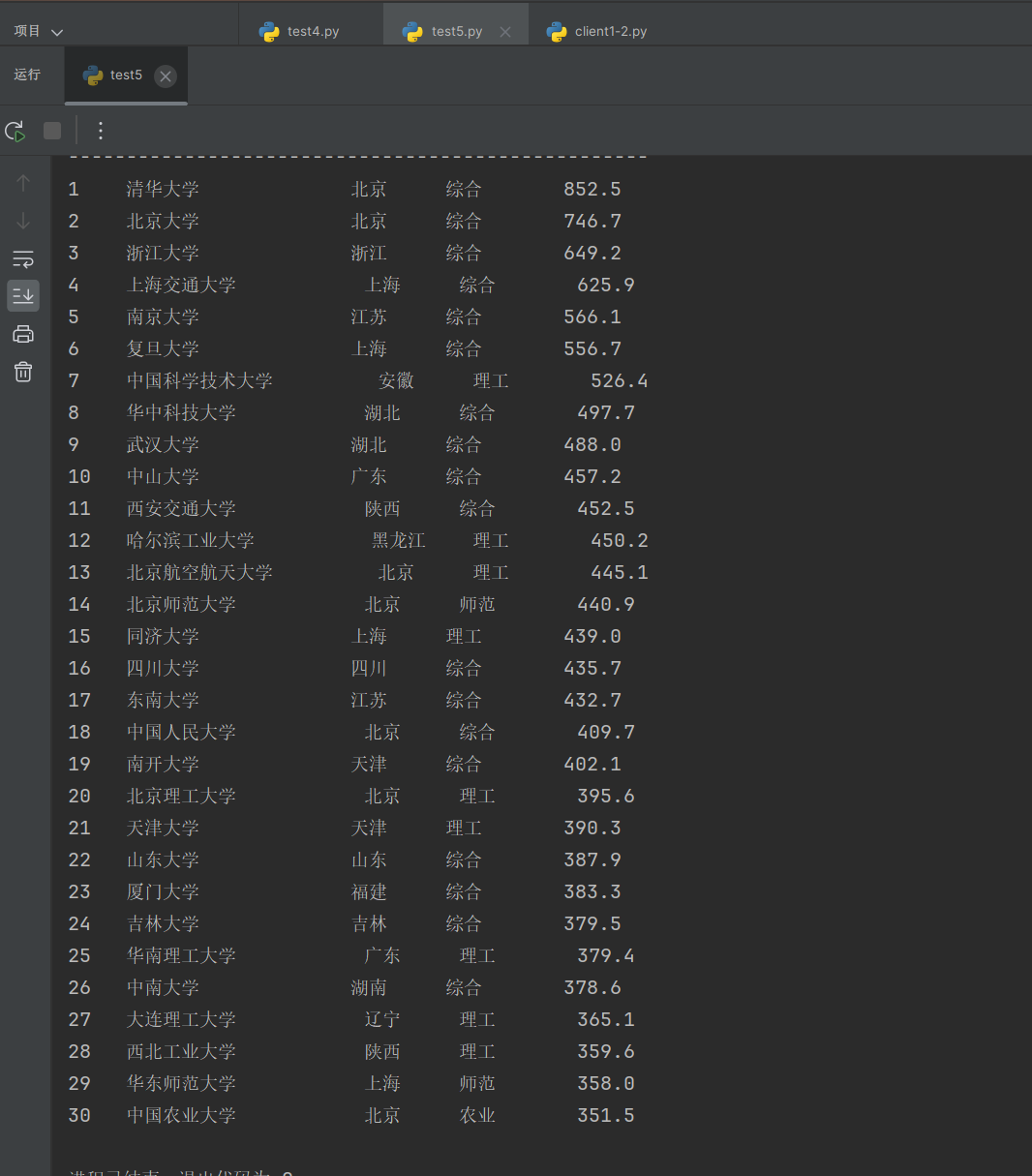
print("-" * 50)for tr in trs:tds = tr.find_all('td')if len(tds) < 5:continuetry:rank = tds[0].text.strip()name_div = tds[1].find('div', class_='univ-name')if name_div:name = name_div.contents[0].strip()else:name = tds[1].get_text().strip().split('\n')[0]province = tds[2].text.strip()type_ = tds[3].text.strip()score = tds[4].text.strip()# 使用字符串格式化对齐print("{:<4} {:<16} {:<6} {:<8} {:<8}".format(rank, name, province, type_, score))except Exception as e:print(f"解析行时出错: {e}")continue
- 运行结果
心得体会-1
在编写爬取代码实践过程中,我掌握了requests库发送HTTP请求和BeautifulSoup解析HTML文档的基本方法,学会了如何分析网页结构定位目标数据。
作业二:
实验过程及结果-2
(1)数据获取阶段,与作业一不同的是,京东、淘宝这些网址往往都具有反爬虫机制,尽管当当网的检查较为宽松,也需要伪造成浏览器进行访问
(2)打开开发者工具,搜索<meta标签,得知网页的编码方式为gb2312
(3)先随便找一个商品,查看标签树结构,这里选择网页的第一个商品,得知其父级标签为li,其class属性中都包含line,因此可以通过line搜索商品

(4)题目要求输出价格和商品名,进一步观察发现,价格和商品名的class属性值分别为price和name
(5)得知标签树的基本结构后,可以通过遍历每个商品项items,从中获取题目要求的价格与商品名。对于商品名,网站中title属性中的内容已经是纯文本,可以直接提取下来。但对于价格,其中的内容包含一些特殊符号,需要通过正则表达式过滤

- 完整代码
点击查看代码
import requests
from bs4 import BeautifulSoup
import redef bs4_dangdang_spider():url = "http://search.dangdang.com/?key=%CA%E9%B0%FC"headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'}try:print("正在获取当当网数据...")response = requests.get(url, headers=headers, timeout=15)response.encoding = 'gb2312'soup = BeautifulSoup(response.text, 'html.parser')products = []# 查找商品列表项items = soup.find_all('li', class_=re.compile('line'))print(f"找到商品项: {len(items)} 个")for item in items:try:# 提取商品名称name_elem = item.find('a', title=True)if not name_elem:continuename = name_elem.get('title', '').strip()if not name or '书包' not in name:continue# 提取价格price_elem = item.find('span', class_=re.compile('price'))if price_elem:price_text = price_elem.get_text()price_match = re.search(r'[\d.]+', price_text)if price_match:price = price_match.group()products.append({'name': name, 'price': price})except Exception as e:continue# 输出结果print("\n序号\t价格\t商品名")print("-" * 80)if products:for i, product in enumerate(products[:20], 1):short_name = product['name'][:50] + "..." if len(product['name']) > 50 else product['name']print(f"{i}\t{product['price']}\t{short_name}")else:print("未找到商品数据")except Exception as e:print(f"错误: {e}")# 运行
if __name__ == "__main__":bs4_dangdang_spider()
- 运行结果

心得体会-2
当当网的反爬机制还是比较友好的,标签树也很清晰,正则表达式比较好写
作业三:
实验过程及结果-3
(1)与第二题一样,先去网页中观察一下html的结构,得知图片信息就藏在img标签后面。由于题目只要求所有JPEG、JPG或PNG格式图片文件下载下来,故而不需要像第二题一样仔细查看属性值,只需查找所有img标签下符合要求的照片,正则表达式:r'\.(jpe?g|png)'

(2)由于网页中的图片链接通常是相对路径,所以我们需要将基础URL和从img标签获取的src属性值组合成完整URLfull_url = urljoin(url, src)
- 完整代码
点击查看代码
import requests
from bs4 import BeautifulSoup
import os
from urllib.parse import urljoin
import re# 请求头
url = "https://news.fzu.edu.cn/yxfd.htm"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"}# 创建下载目录
if not os.path.exists("download"):os.makedirs("download")# 获取网页内容
resp = requests.get(url, headers=headers)
resp.encoding = resp.apparent_encoding
soup = BeautifulSoup(resp.text, 'html.parser') cnt = 0
# 遍历所有图片标签
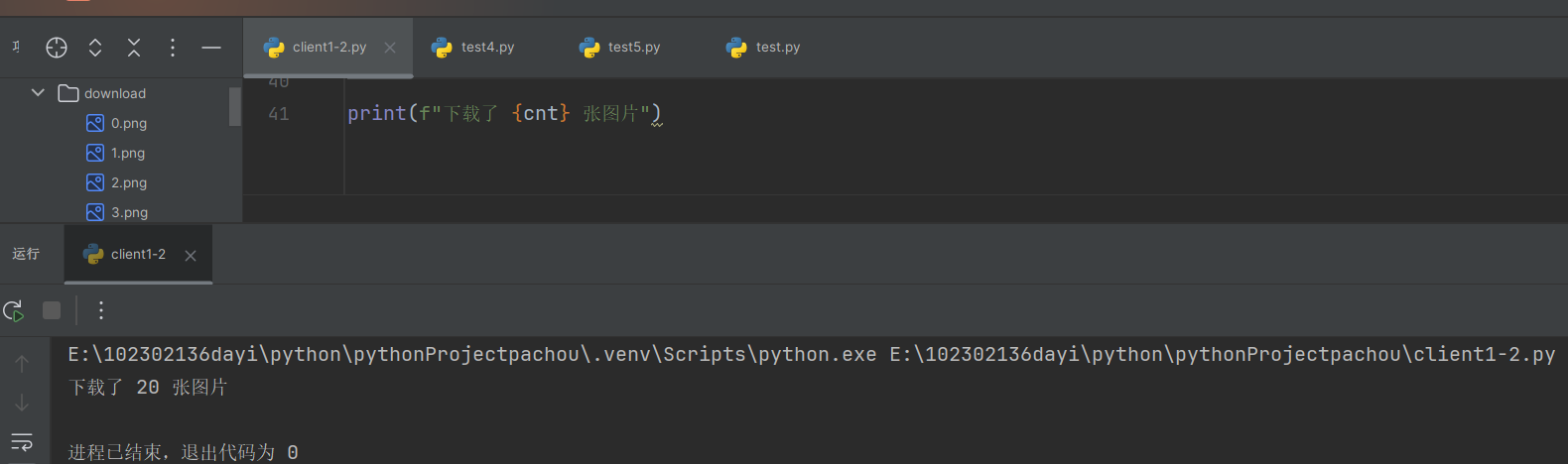
for img in soup.find_all('img'):src = img.get('src', '') # 获取图片链接if src:full_url = urljoin(url, src) # 拼接完整URL# 检查是否为jpg或png图片if re.search(r'\.(jpe?g|png)', full_url, re.IGNORECASE):try:img_resp = requests.get(full_url, headers=headers)if img_resp.status_code == 200:# 根据URL确定文件扩展名extension = '.jpg' if re.search(r'\.jpe?g', full_url, re.IGNORECASE) else '.png'with open(f"download/{cnt}{extension}", "wb") as f:f.write(img_resp.content)cnt += 1except:pass print(f"下载了 {cnt} 张图片")
- 运行结果

心得体会-3
一开始忽略了URL拼接的重要性,导致图片无法下载,通过添加urljoin解决了路径问题。也学会了正则表达式筛选图片格式,以及文件保存。