Redis数据安全性分析
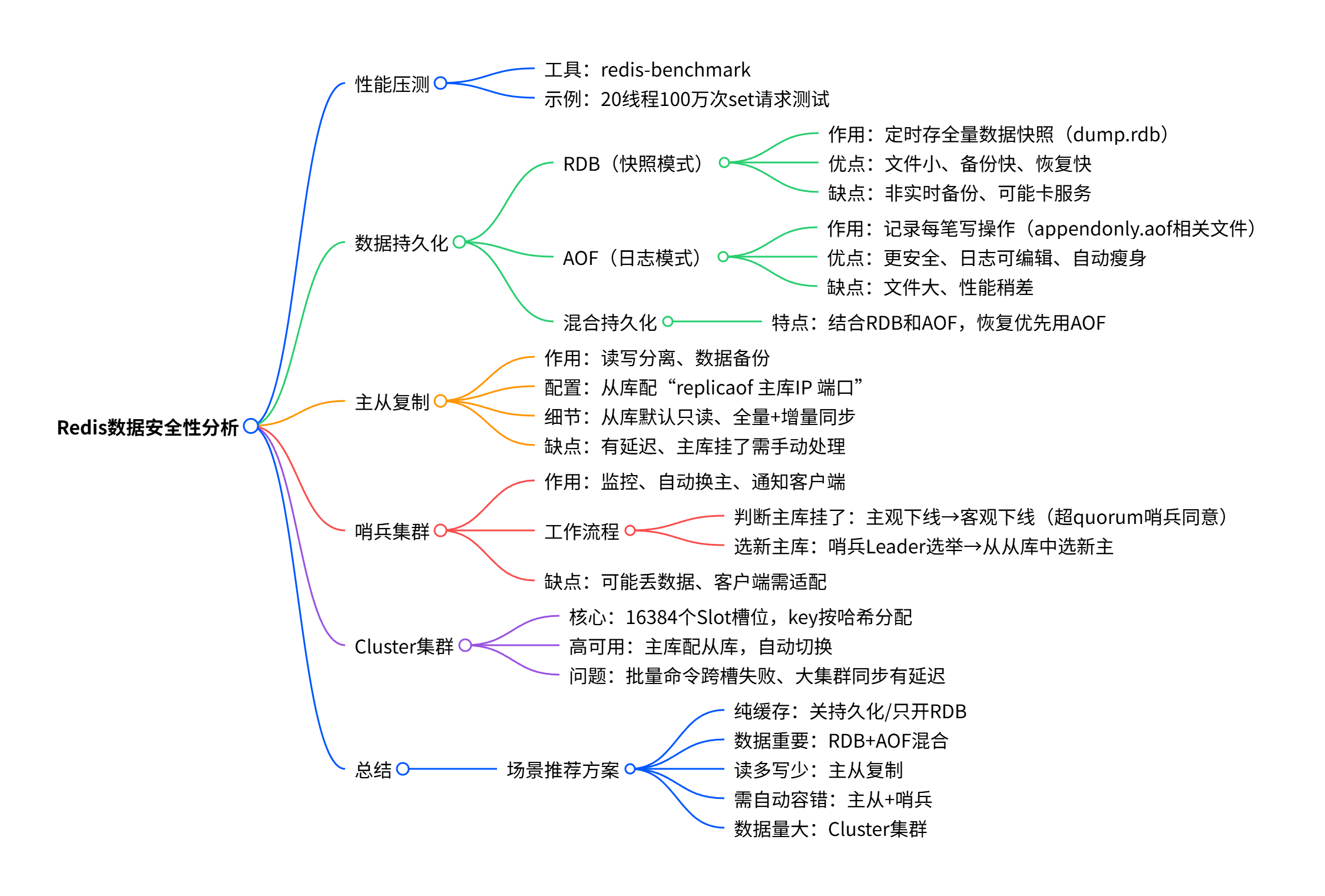
一、性能压测:先搞懂 Redis 能扛多少活儿
Redis 自带一个压测工具redis-benchmark,能快速测试性能,帮你判断 Redis 在当前配置下的极限。
比如:用 20 个线程发 100 万次set指令(写数据),命令是:
redis-benchmark -a 密码 -t set -n 1000000 -c 20
结果会显示 “每秒处理约 11 万次请求”,这样就能大概知道 Redis 的承载能力,再根据业务调整配置。
二、数据持久化:防止 Redis 断电丢数据
Redis 数据存在内存里,断电就没了。持久化机制就是把内存数据存到硬盘,分三种策略:
1. RDB(快照模式):定时 “拍照片”
- 作用:按设定的时间间隔,把内存里的所有数据 “拍个快照”,存成
dump.rdb文件(二进制,体积小)。
比如默认配置:1 小时内改了 1 次、5 分钟内改了 100 次、1 分钟内改了 1 万次,就自动存一次。 - 优点:
- 文件小,适合备份(比如每天凌晨存一次,用于灾难恢复);
- 备份时不卡主线程(开个小线程干活);
- 恢复数据快(直接读整个快照)。
- 缺点:
- 不能实时备份,万一断电,最近一次快照后的修改会丢失;
- 数据量大时,“拍快照” 可能短暂卡主服务(复制内存数据时耗资源)。
2. AOF(日志模式):实时 “写日记”
- 作用:把每一次写操作(比如
set、incr)记成日志,存到appendonly.aof相关文件里。恢复时,重放日志就能还原数据。 - 优点:
- 更安全:默认每秒存一次日志,最多丢 1 秒的数据;
- 日志可编辑:比如误删数据,删了日志里的
FLUSHALL命令,重启就恢复了; - 日志太大时会自动 “瘦身”(合并重复命令,比如多次
incr合并成一个set)。
- 缺点:
- 日志文件比 RDB 大;
- 写日志频繁时,性能比 RDB 稍差。
3. 混合持久化:“照片 + 日记” 结合
Redis 7 以后支持同时开 RDB 和 AOF,日志里既有 RDB 的快照(快速恢复),又有 AOF 的增量操作(少丢数据)。恢复时优先用 AOF(数据更全)。
三、主从复制:一份数据存多份,读写分开
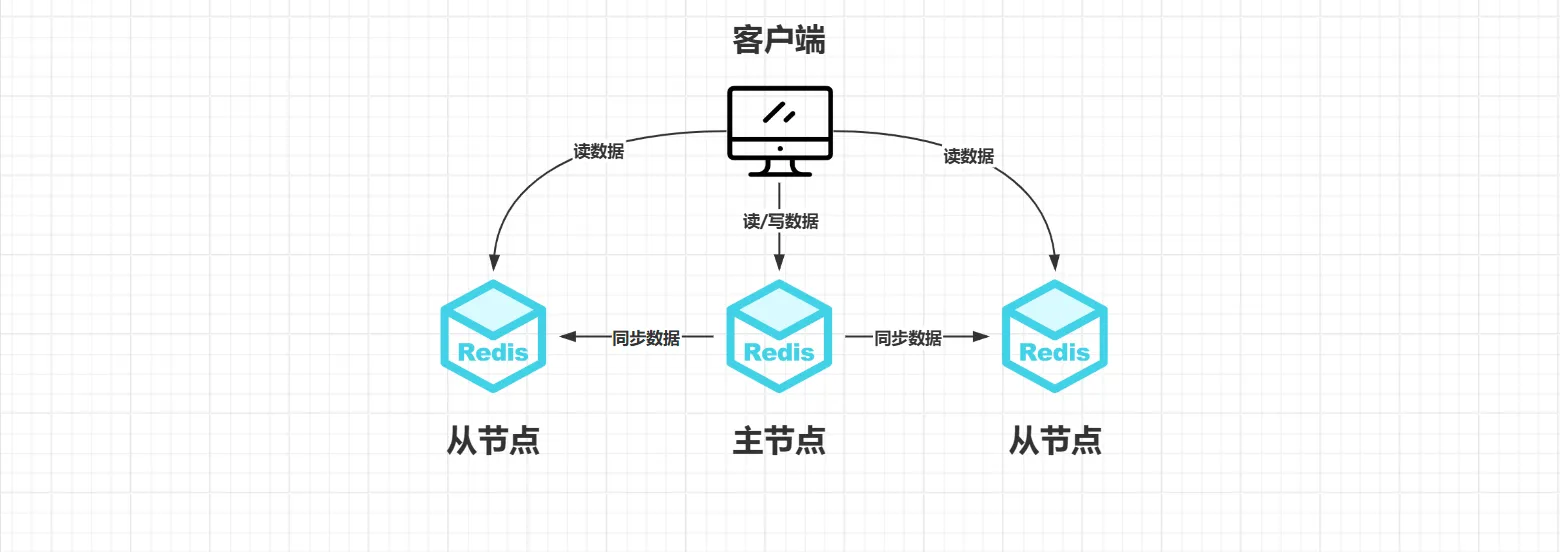
1. 作用
- 读写分离:主库(master)负责写,从库(slave)负责读,减轻主库压力;
- 备份:从库实时同步主库数据,主库挂了还有从库兜底。
2. 怎么配?
- 核心原则:“配从不配主”—— 给从库配置 “跟着哪个主库”,主库不用管。
比如在从库的redis.conf里加:replicaof 主库IP 主库端口。
3. 关键细节
-
从库默认只读:防止从库改数据导致不一致(想改可以关
replica-read-only配置,但不建议); -
同步流程:
1.从库刚启动时,主库发全量数据(RDB 快照);
2.之后主库有新操作,实时发增量数据给从库;
-
怎么看状态:用
info replication命令,主库能看到连了几个从库,从库能看到主库是否在线。
4. 缺点
- 延迟:主库写了数据,从库同步有延迟,极端情况可能读到旧数据;
- 主库挂了要手动救:从库不会自动变主库,得人工操作。
四、哨兵集群:自动给 Redis “找新主”
主从复制怕主库挂了没人管,哨兵(Sentinel)就是来自动处理这个问题的。
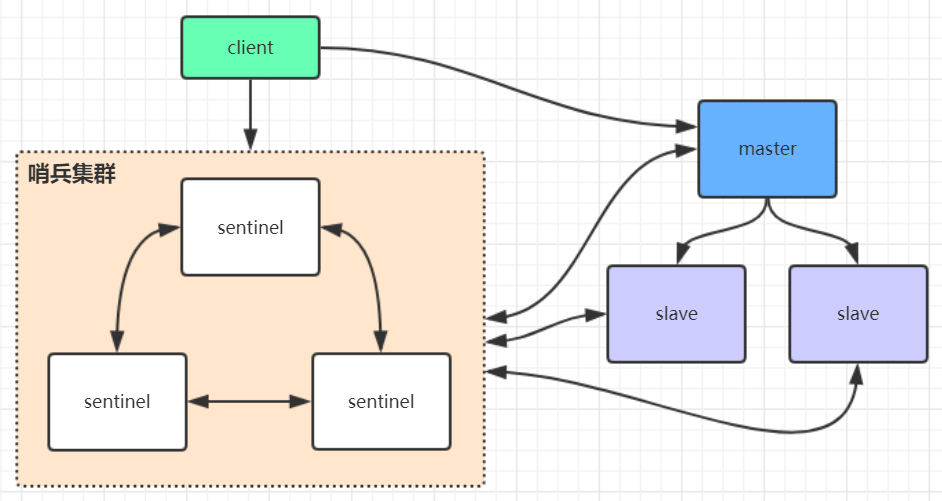
1. 作用
- 监控:盯着主库和从库是否活着;
- 自动换主:主库挂了,自动从从库里选一个当新主库;
- 通知客户端:告诉客户端 “新主库是谁”。
2. 怎么工作?
- 判断主库挂了:
- 单个哨兵觉得主库没响应(30 秒没动静),叫 “主观下线”(可能是网络卡了);
- 超过
quorum个哨兵都觉得主库挂了(比如 3 个哨兵里 2 个同意),才叫 “客观下线”(真挂了)。
- 选新主库流程:
- 哨兵们投票选一个 “领导”(Leader),负责指挥换主;
- 从健康的从库里挑新主:优先选配置优先级高的(
replica-priority小的)→ 数据最新的(同步进度快的)→ 按 ID 排序选小的。
3. 缺点
- 主库挂了时,没来得及同步到从库的数据会丢;
- 客户端得支持 “跟着哨兵找新主库”,不然写请求会失败。
五、Cluster 集群:数据太多?分了存!
主从、哨兵适合小规模数据,数据量太大(比如几十 GB)时,用 Cluster 集群把数据分到多个主库。
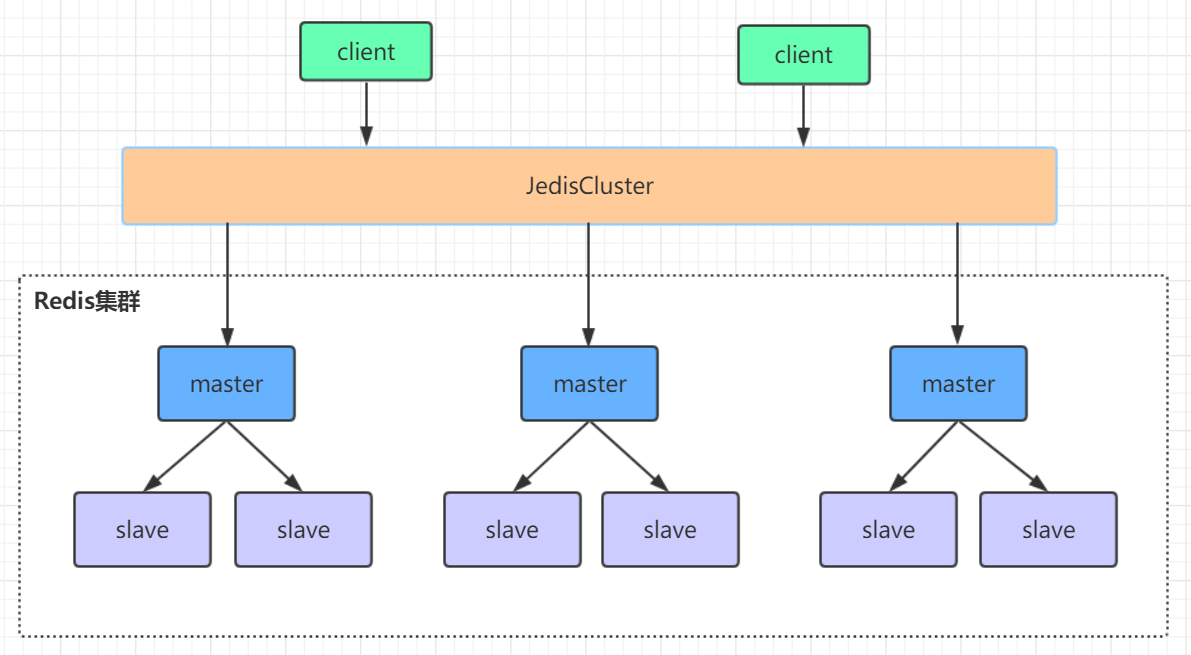
1. 核心:Slot 槽位(类似快递分拣)
- 总共 16384 个 “槽位”,每个 key 按公式(
CRC16(key) % 16384)分到某个槽位; - 每个主库负责一部分槽位(比如 3 个主库,分别管 0-5460、5461-10922、10923-16383);
- 客户端写数据时,自动找到 key 对应的槽位所在的主库,不用手动切换。
2. 高可用
- 每个主库配一个从库,主库挂了,从库自动变主库;
- 新增节点时,会重新分配槽位(叫
reshard),数据跟着槽位迁移,不用全量搬。
3. 小问题
- 批量命令(比如
mset)如果 key 分到不同槽位,会失败(跨槽不支持); - 集群太大时,节点间同步信息有延迟(用
gossip协议慢慢传)。
gossip协议包含多种消息,包括ping,pong,meet,fail等等。
六、总结:怎么选方案?
| 场景 | 推荐方案 | 优点 | 缺点 |
|---|---|---|---|
| 纯缓存(丢点数据没事) | 关持久化 / 只开 RDB | 性能高 | 可能丢数据 |
| 数据重要(少丢数据) | RDB+AOF 混合持久化 | 安全 + 恢复快 | 略影响性能 |
| 读多写少,需备份 | 主从复制 | 读写分离,减轻主库压力 | 主库挂了要手动换 |
| 需自动容错 | 主从 + 哨兵 | 主库挂了自动换,高可用 | 可能丢少量未同步数据 |
| 数据量大(超 10GB) | Cluster 集群 | 数据分片,支持大规模 | 批量命令受限,配置稍复杂 |
Redis 现在也能当数据库用(尤其企业版 / 云服务),但一般还是建议当缓存,配合数据库用更稳妥~
Redis几种安装模式
单机模式的配置
1.检查安装环境
-- 安装gcc,redis基于C语言开发的,需要C环境的支持
yum install gcc
-- 关闭以及卸载防火墙,这里是为了本地方便测试
systemctl stop firewalld
yum remove firewalld
centos7官方已经停止维护镜像,可以替换为国产的阿里云等镜像
2.下载并安装Redis
-- 下载redis最新的发行版源码
mkdir -p /opt/software/redis
cd /opt/software/redis
wget https://download.redis.io/redis-stable.tar.gz
-- 解压并进入路径下编译源码安装
tar -xzf redis-stable.tar.gz
cd redis-stable
make install
安装成功后会多出以下命令
[root@192 ~]# ls /usr/local/bin/
redis-benchmark redis-check-aof redis-check-rdb redis-cli redis-sentinel redis-server
| 工具名称 | 功能描述 |
|---|---|
| redis-benchmark | Redis 性能测试工具,可模拟多线程请求测试吞吐量等性能指标 |
| redis-check-aof | 修复存在问题的 AOF(Append Only File)持久化文件 |
| redis-check-rdb | 修复存在问题的 RDB(Redis Database)持久化文件 |
| redis-sentinel | Redis 哨兵集群相关工具,用于实现主从集群的高可用(监控、故障转移等) |
| redis-server | Redis 服务器的启动命令,用于启动 Redis 服务进程 |
| redis-cli | Redis 客户端工具,是操作 Redis 服务的入口,可发送命令与服务器交互 |
3.调整配置文件,并启动
- 修改redis目录下的
redis.conf,以下是常用的配置项,版本不同位置有所区别
bind * -::* #87⾏,修改bind 项,* -::* ⽀持远程连接
daemonize yes #309⾏,开启守护进程,后台运⾏
logfile /opt/software/redis/redis-stable/redis.log #355⾏,指定⽇志⽂件⽬录
dir /opt/software/redis #510⾏,指定⼯作⽬录
requirepass 1234 #1044⾏,给默认⽤户设置密码,主要是使⽤ redis-cli 连接 redis-server时,需要通过密码校验。⾃⾏学习,可以不设置。
protected-mode no #111⾏,允许远程连接 如果不设置密码必须讲此设置关闭。
- 启动redis服务
redis-server redis.conf #指定配置文件启动服务端
redis-cli -a 1234 #通过客户端连接redis服务
主从复制的配置
# 添加主节点信息
replicaof 192.168.150.100 6379
# 主节点查看从节点信息
info Replication
只需要在从节点中添加此配置即可,主节点无需任何改动
哨兵集群的配置
从图中可以看出,哨兵模式是在主从复制的基础上,额外增加三台机器组成了哨兵集群。
protected-mode no #6⾏,关闭保护模式
daemonize yes #15⾏,指定sentinel为后台启动
logfile /opt/software/redis/redis-stable/sentinel.log #34⾏,指定⽇志存放路径
dir /opt/software/redis #73⾏,指定数据库存放路径
#93⾏,修改 指定该哨兵节点监控192.168.150.100:6379这个主节点,该主节点的名称是mymaster,最后的2的含义与主节点的故障判定有关:⾄少需要2个哨兵节点同意,才能判定主节点故障并进⾏故障转移
sentinel monitor mymaster 192.168.150.100 6379 2
sentinel down-after-milliseconds mymaster 30000 #134⾏,判定服务器down掉的时间周期,默认30000毫秒(30秒)
sentinel failover-timeout mymaster 180000 #234⾏,故障节点的最⼤超时时间为180000(180秒)
查看哨兵节点的状态: redis-cli -p 26379 info sentinel
当触发哨兵选举之后,会自动在redis.conf与sentinel.conf末尾追加节点变更信息;
本地测试时,可以在一台机器上启动三个redis实例(复制三份配置文件),在另一台机器上启动三个redis实例作为哨兵
Cluster集群的配置
我们这里以三主三从模式为例来部署集群:在六台机器中复制以下配置文件,修改端口与相关路径
# 允许所有的IP地址
bind * -::*
# 后台运⾏
daemonize yes
# 允许远程连接
protected-mode no
# 开启集群模式
cluster-enabled yes
# 集群节点超时时间
cluster-node-timeout 5000
# 配置数据存储⽬录
dir "/opt/software/redis/cluster"
# 开启AOF持久化
appendonly yes
# 端⼝
port 6380
# log⽇志
logfile "/opt/software/redis/redis-stable/cluste
r/redis6380.log"
# 集群配置⽂件
cluster-config-file nodes-6380.conf
# AOF⽂件名
appendfilename "appendonly6380.aof"
# RBD⽂件名
dbfilename "dump6380.rdb
检查启动:ps -ef | grep redis-server
建立集群:redis-cli --cluster create --cluster-replicas 1 192.168.150.100:6379 192.168.150.101:6379 192.168.150.102:6379 192.168.150.100:6380 192.168.150.101:6380 192.168.150.102:6380
--cluster-replicas后面的1代表每个主节点带一个从节点,redis会自动选择命令中前几个作为主节点
常用指令:
-- 查看集群信息
redis-cli cluster info
-- 查看单个节点信息
redis-cli info replication
-- 查看集群节点身份信息
redis-cli cluster nodes
-- 停⽌redis服务
redis-cli -p 6379 shutdown
redis-cli -p 6380 shutdown
Redis集群中的进阶问题
Redis集群选举原理分析
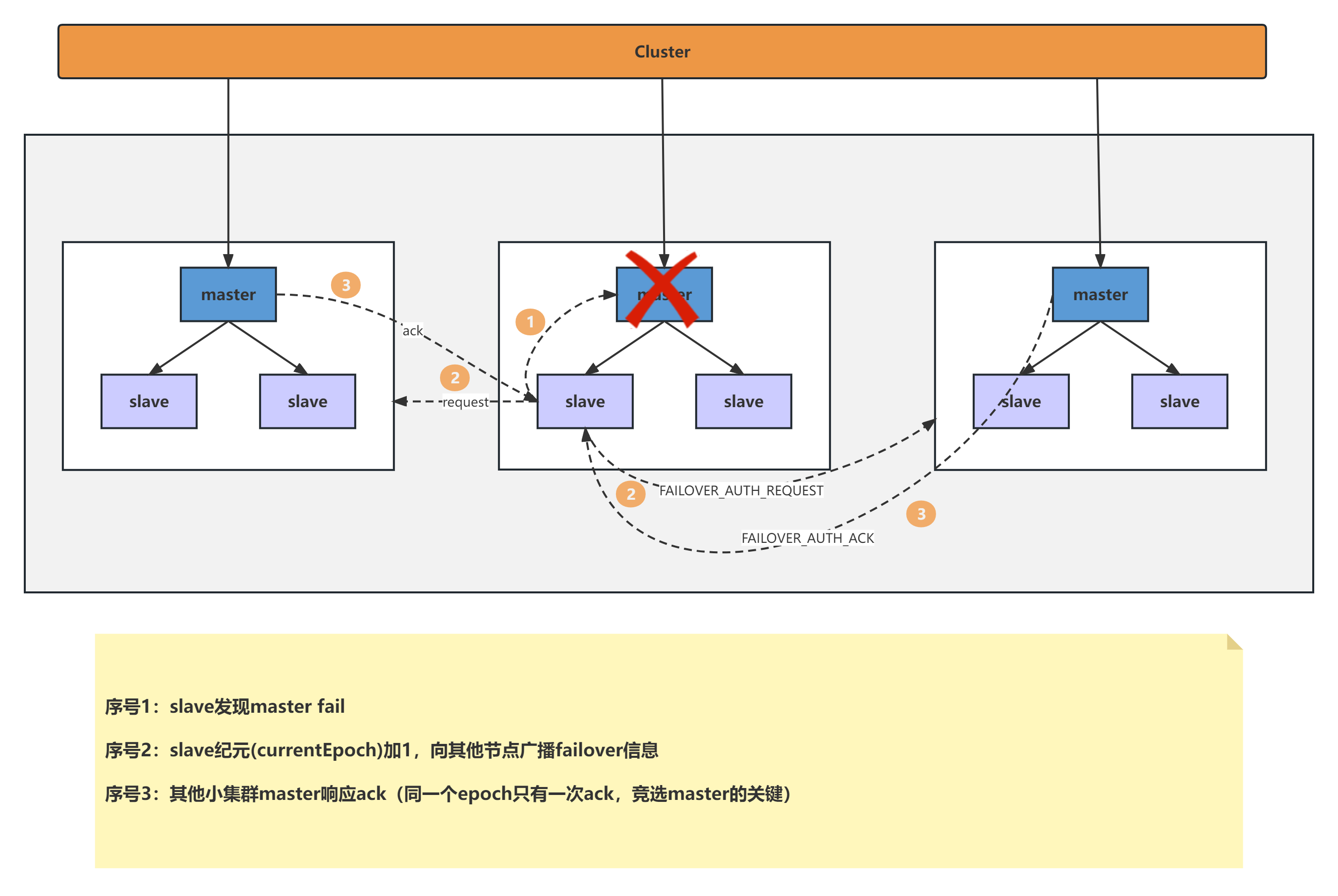
当slave发现自己的master变为FAIL状态时,便尝试进行Failover,以期成为新的master。由于挂掉的master可能会有多个slave,从而存在多个slave竞争成为master节点的过程, 其过程如下:
-
slave发现自己的master变为FAIL
-
将自己记录的集群currentEpoch加1,并广播FAILOVER_AUTH_REQUEST 信息
-
其他节点收到该信息,只有master响应,判断请求者的合法性,并发送FAILOVER_AUTH_ACK,对每一个epoch只发送一次ack
-
尝试failover的slave收集master返回的FAILOVER_AUTH_ACK
-
slave收到超过半数master的ack后变成新Master(这里解释了集群为什么至少需要三个主节点,如果只有两个,当其中一个挂了,只剩一个主节点是不能选举成功的)
-
slave广播Pong消息通知其他集群节点。
从节点并不是在主节点一进入 FAIL 状态就马上尝试发起选举,而是有一定延迟,一定的延迟确保我们等待FAIL状态在集群
传播,slave如果立即尝试选举,其它masters或许尚未意识到FAIL状态,可能会拒绝投票(序号3会做合法性验证)
- 延迟计算公式:
DELAY = 500ms + random(0 ~ 500ms) + SLAVE_RANK * 1000ms - SLAVE_RANK表示此slave已经从master复制数据的总量的rank。Rank越小代表已复制的数据越新。这种方式下,持有最新数据的slave将会首先发起选举(理论上)。
集群脑裂数据丢失问题
redis集群没有过半机制会有脑裂问题,网络分区导致脑裂后多个主节点对外提供写服务,一旦网络分区恢复,会将其中一个主节点变为从节点,这时会有大量数据丢失。
规避方法可以在redis配置里加上参数(这种方法不可能百分百避免数据丢失,参考集群leader选举机制:
#写数据成功最少同步的slave数量,这个数量可以模仿大于半数机制配置,
#比如集群总共三个节点可以配置1,加上leader就是2,超过了半数
min‐replicas‐to‐write 1
这个配置在一定程度上会影响集群的可用性,比如slave要是少于1个,这个集群就算leader正常也不能
提供服务了,需要具体场景权衡选择。
集群是否完整才能对外提供服务
当redis.conf的配置cluster-require-full-coverage为no时,表示当负责一个插槽的主库下线且没有相应的从库进行故障恢复时,集群仍然可用,如果为yes则集群不可用。
Redis集群为什么至少需要三个master节点,并且推荐节点数为奇数?
因为新master的选举需要大于半数的集群master节点同意才能选举成功,如果只有两个master节点,当其中一个挂了,是达不到选举新master的条件的。
奇数个master节点可以在满足选举该条件的基础上节省一个节点,比如三个master节点和四个master节点的集群相比,大家如果都挂了一个master节点都能选举新master节点,如果都挂了两个master节点都没法选举新master节点了,所以奇数的master节点更多的是从节省机器资源角度出发说的。
Redis集群对批量操作命令的支持
对于类似mset,mget这样的多个key的原生批量操作命令,redis集群只支持所有key落在同一slot的情况,如果有多个key一定要用mset命令在redis集群上操作,则可以在key的前面加上{XX},这样参数数据分片hash计算的只会是大括号里的值,这样能确保不同的key能落到同一slot里去,示例如下:
mset {user1}:1:name zhuge {user1}:1:age 18
假设name和age计算的hash slot值不一样,但是这条命令在集群下执行,redis只会用大括号里的 user1 做hash slot计算,所以算出来的slot值肯定相同,最后都能落在同一slot。
哨兵leader选举流程
当一个master服务器被某sentinel视为下线状态后,该sentinel会与其他sentinel协商选出sentinel的leader进行故障转移工作。每个发现master服务器进入下线的sentinel都可以要求其他sentinel选自己为sentinel的leader,选举是先到先得。同时每个sentinel每次选举都会自增配置纪元(选举周期epoch),每个纪元中只会选择一个sentinel的leader。如果所有超过一半的sentinel选举某sentinel作为leader。之后该sentinel进行故障转移操作,从存活的slave中选举出新的master,这个选举过程跟集群的master选举很类似。
哨兵集群只有一个哨兵节点,redis的主从也能正常运行以及选举master,如果master挂了,那唯一的那个哨兵节点就是哨兵leader了,可以正常选举新master。
不过为了高可用一般都推荐至少部署三个哨兵节点。为什么推荐奇数个哨兵节点原理跟集群奇数个master节点类似