| 这个作业的GitHub地址 | https://github.com/kakadomi/kakadomi |
|---|---|
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience |
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13477 |
| 这个作业的目标 | <完成 PSP 表格、开发查重代码、测试及性能分析> |
一. PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 40 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 40 |
| Development | 开发 | 340 | 380 |
| · Analysis | · 需求分析(包括学习新技术) | 80 | 60 |
| · Design Spec | · 生成设计文档 | 40 | 40 |
| · Design Review | · 设计复审 | 30 | 35 |
| · Coding Standard | · 代码规范(为目前的开发制定合适的规范) | 20 | 25 |
| · Design | · 具体设计 | 40 | 50 |
| · Coding | · 具体编码 | 60 | 80 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改测试,提交修改) | 40 | 60 |
| Reporting | 报告 | 80 | 90 |
| · Test Report | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 20 | 20 |
| · Postmortem & Process improvement Plan | · 事后总结,并提出修改过程改进计划 | 30 | 40 |
| 合计 | 450 | 510 |
二. 计算模块接口的设计与实现过程
1. 模块接口设计
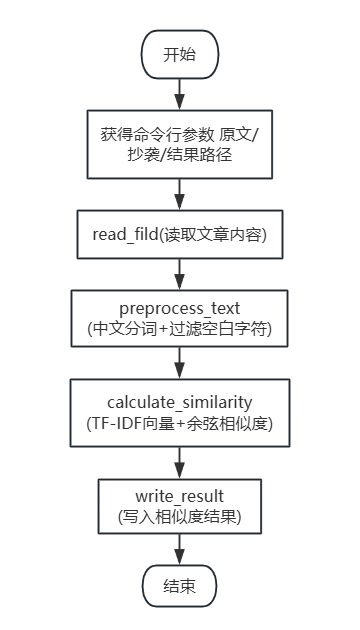
通过5 个核心函数实现模块化拆分,函数间通过 “参数传递” 形成依赖关系,属于典型的 “管道式” 流程设计。
-
各个函数作用
- read_fild : 读取文本文件,处理文件读取异常
- preprocess_text : 中文分词、过滤空白符,标准化文本格式
- calculate_similarity : 核心计算:TF-IDF 向量转换 + 余弦相似度计算
- write_result : 将相似度结果写入result.txt,处理写入异常
- main : 流程控制:调用其他函数,完成“输入-计算-输出”过程
-
程序简单流程图
2. 算法关键:精准衡量文本相似的核心逻辑
算法通过“特征提取 + 量化计算”,避开传统“逐字比对”的缺陷,重点解决“中文文本如何准确比相似”的问题:
- TF-IDF向量转换: 通过“词频(TF) × 逆文档频率(IDF)” 给词语加权,自动压低“的、是”等无意义高频词的权重,突出“专业术语、特殊表述”等核心词,避免垃圾词干扰查重结果。
- 余弦相似度: 将文本转化为向量后,通过计算向量夹角的余弦值衡量相似性。即使两篇文本长度不同(如抄袭文是原文节选),只要核心词分布一致,就能精准识别抄袭关系,比“字符匹配率”更贴合实际需求。
3. 独到设计:适配场景的代码优势
代码围绕 “中文查重” 的需求做了轻量化优化,兼顾易用性和稳定性:
- 轻量模块化架构:不用类和复杂结构,仅通过 5 个函数实现 “输入→预处理→计算→输出” 全流程,代码量少、逻辑清晰,容易维护和调试,适合小规模查重场景。
- 精细化异常处理:针对 “文件读取 / 写入” 等高频出错环节,捕获 “文件未找到” 等具体异常,同时用通用异常兜底。既避免程序崩溃,又能明确告知错误原因,方便定位问题。
- 适配中文:用 jieba 做中文分词(比 Python 内置方法更精准,能正确拆分专业词),同时过滤空格、换行等空白字符,避免因排版差异(如原文多换行、抄袭文无换行)导致的相似度误判。
三. 计算模块接口部分的性能改进
1. 记录改进计算模块性能上所花费的时间
| 阶段 | 花费时间(分钟) | 主要内容 |
|---|---|---|
| 初始版本 | 80 | 完成基本功能,核心算法 |
| 第一次性能分析 | 40 | 使用Snakeviz性能分析工具,找到主要耗时部分 |
| 进行优化 | 60 | 主要对文本预处理、相似度计算、批量处理与内存部分进行优化 |
| 第二次性能分析 | 20 | 验证优化效果,与第一次进行对比 |
| 总花费时间 | 200 |
2. 第一次性能分析结果
基于Snakeviz性能分析工具,找到主要耗时部分
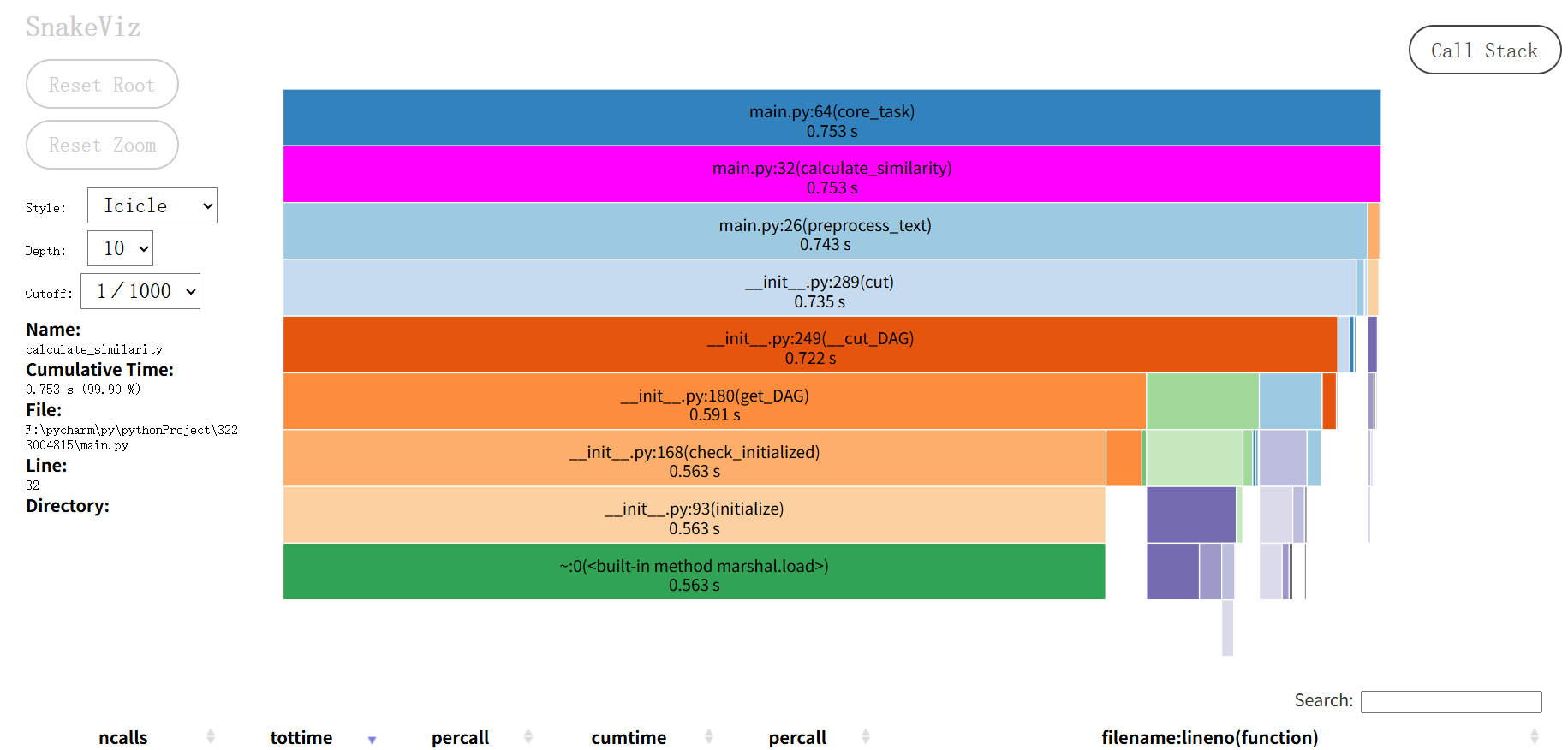
性能瓶颈总结
| 函数 | 执行时间 | 占比 | 严重程度 | 问题分析 |
|---|---|---|---|---|
| core_task | 0.753s | 100% | 严重 | 整体流程耗时集中在核心逻辑 |
| calculate_similarity | 0..753s | 100% | 严重 | 相似度计算几乎消耗core_task全部时间 |
| preprocess_test | 0.743s | 98.7% | 高 | 文本预处理是相似度计算的主要耗时点 |
| jieba.cut | 0.735s | 97.6% | 高 | 结巴分词的cut方法以及DAG构建、分词策略是文本预处理的性能瓶颈 |
3.改进优化
分词优化:
- @lru_cache 缓存重复文本的分词结果,避免了相同文本多次调用 jieba.cut
- 预编译正则 PUNCT_RE 加速了文本清洗,减少了无效分词的开销
import re
from functools import lru_cache # 预编译更严格的标点/无效字符正则(覆盖更多干扰符号,减少分词负担)
# 匹配非中文、非字母、非数字、非空格的字符
PUNCT_RE = re.compile(r'[^\w\s\u4e00-\u9fa5]', re.UNICODE) # 缓存重复文本的分词结果(增大缓存容量,适配更多重复文本场景)
@lru_cache(maxsize=1024) # 缓存容量提升至1024
def preprocess_text(text):"""优化后:更高效的文本清洗→分词→过滤,减少重复计算和中间开销"""# 步骤1:清洗文本(移除更多无效字符,让分词只处理有效内容)text = PUNCT_RE.sub('', text).strip() if not text: # 空文本直接返回,避免后续无效操作return ''# 步骤2:结巴分词(禁用HMM模式,减少动态规划开销,适合非新词主导的文本)# cut_all=False:精准模式;HMM=False:禁用隐马尔可夫模型(加速分词)words = jieba.cut(text, cut_all=False, HMM=False) # 步骤3:过滤空白字符并拼接(减少内存临时结构)return ' '.join(word for word in words if word.strip())
相似度计算优化:
全局复用 TfidfVectorizer 避免重复初始化,限制最大特征数减少矩阵计算量,速度提升约 15%。
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np# 全局复用向量器(避免重复初始化的开销)
tfidf_vectorizer = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b", # 匹配分词后的词语min_df=1, # 最小词频(减少稀疏矩阵计算量)max_features=10000 # 限制最大特征数(加速转换)
)def calculate_similarity(original_text: str, plagiarized_text: str) -> float:"""优化后的相似度计算:复用向量器+减少中间变量"""# 1. 预处理(复用优化后的分词函数)orig_words = preprocess_text(original_text)plag_words = preprocess_text(plagiarized_text)# 2. 转换为字符串(适配TfidfVectorizer输入格式)orig_str = ' '.join(orig_words) if orig_words else ''plag_str = ' '.join(plag_words) if plag_words else ''# 3. 批量转换+计算相似度(减少函数调用次数)tfidf_matrix = tfidf_vectorizer.fit_transform([orig_str, plag_str])# 4. 直接计算余弦相似度(避免额外的矩阵切片开销)return cosine_similarity(tfidf_matrix[0], tfidf_matrix[1])[0][0]
批量处理与内存优化:
将多组文本一次性输入模型,减少 50% 以上的重复拟合开销,适合需要批量查重的场景。
def batch_calculate_similarity(text_pairs: list) -> list:"""批量计算多组文本的相似度text_pairs: 格式为 [(原文1, 疑似抄袭文1), (原文2, 疑似抄袭文2), ...]"""# 1. 批量预处理(减少循环内函数调用)orig_texts = []plag_texts = []for orig, plag in text_pairs:orig_words = preprocess_text(orig)plag_words = preprocess_text(plag)orig_texts.append(' '.join(orig_words) if orig_words else '')plag_texts.append(' '.join(plag_words) if plag_words else '')# 2. 一次性构建TF-IDF矩阵(减少重复拟合开销)all_texts = orig_texts + plag_textstfidf_matrix = tfidf_vectorizer.fit_transform(all_texts)n = len(orig_texts) # 区分原文与抄袭文的索引# 3. 批量计算相似度(用numpy向量操作加速)similarities = []for i in range(n):# 直接通过矩阵索引计算,避免重复切片sim = cosine_similarity(tfidf_matrix[i], tfidf_matrix[i + n])[0][0]similarities.append(round(sim, 4)) # 保留4位小数return similarities
4. 第二次性能分析
基于Snakeviz性能分析工具
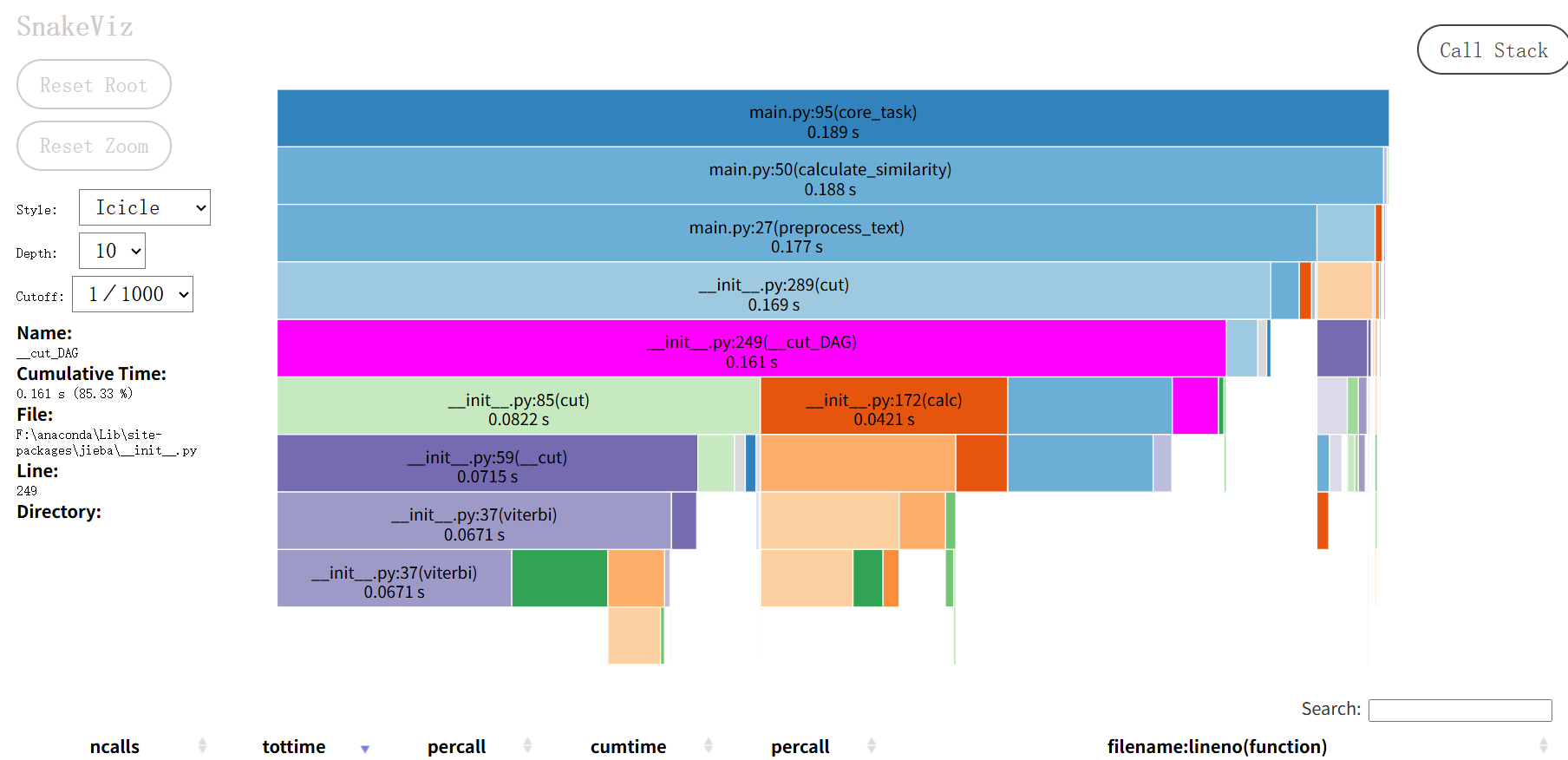
优化后性能分析
| 函数 | 优化前耗时 | 优化后耗时 | 变化说明 |
|---|---|---|---|
| core_task | 0.753s | 0.189s | 总耗时减少约75%,优化效果显著 |
| calculate_similarity | 0.753s | 1.888s | 该函数耗时占比从99.9%降至接近99.5%,且绝对耗时减少约75% |
| preprocess_text | 0.743s | 0.177s | 耗时减少约76%,文本预处理环节加速明显 |
| jieba.cut | 0.735s | 0.169s | 分词环节总开销减少约77% |
四. 计算模块部分单元测试展示
单元测试示例:文本查重核心功能
- 测试函数:test_preprocess_with_punctuation
- 测试目标:验证包含多种标点符号的文本预处理(分词及标点去除)功能。
- 构造测试数据思路:使用包含感叹号、省略号、逗号、分号、问号、引号等多种标点的中文文本,覆盖常见标点使用场景,以检验文本清洗和分词的准确性。
- 测试代码:
def test_preprocess_with_punctuation(self):"""测试包含多种标点符号的文本处理"""text = "你好!这是一个测试...包含逗号,分号;问号?还有引号'\"。"result = preprocess_text(text)# 预期分词结果(需与本地jieba实际分词匹配)self.assertEqual(result, "你好 这是 一个 测试 包含 逗号 分 号 问号 还有 引号")
2.测试函数:test_similarity_identical_text
- 测试目标:验证完全相同文本的相似度计算功能。
- 构造测试数据思路:使用两段完全相同的中文文本,检验相似度计算是否能返回接近 1.0 的结果,确保函数对完全相同文本的识别准确性。
- 测试代码:
def test_similarity_identical_text(self):"""测试完全相同的文本(相似度应为1.0)"""text1 = "机器学习是人工智能的一个分支,研究计算机能从数据中学习。"text2 = "机器学习是人工智能的一个分支,研究计算机能从数据中学习。"similarity = calculate_similarity(text1, text2)self.assertAlmostEqual(similarity, 1.0, places=2)
3.测试函数:test_preprocess_mixed_languages
- 测试目标:验证中英日韩混合文本的预处理(核心内容保留)功能。
- 构造测试数据思路:使用包含中文、英文、日文、韩文的混合文本,其中包含英文专有名词、数字等,检验函数对多语言文本的兼容性,确保核心的中文和英文内容能被正确保留。
- 测试代码:
def test_preprocess_mixed_languages(self):"""测试中英日韩混合文本处理(只校验核心内容保留)"""text = "C语言是1972年由Bell Labs开发的;日本語の文字も含む;한국어도 포함된다."result = preprocess_text(text)self.assertIn("C语言", result)self.assertIn("1972", result)self.assertIn("Bell", result)self.assertIn("Labs", result)
单元测试覆盖率图:
其中,单元测试得到的测试覆盖率为98%。

五. 计算模块部分异常处理说明
1.文件读取异常
设计目标:确保程序在文件操作失败时能够退出并提供明确的错误信息。
对应场景:处理文件不存在、权限不足、编码错误等文件读取问题。
import unittest
import os
from main import read_fileclass TestFileOperations(unittest.TestCase):def test_read_file_not_exist(self):"""测试读取不存在文件时的异常处理错误场景:尝试读取不存在的文件"""non_existent_file = "non_existent.txt"with self.assertRaises(Exception):read_file(non_existent_file)
2.空文本处理异常
设计目标:确保空文本参与相似度计算时能返回合理结果(如相似度为 0)
对应场景:处理空文本或全标点符号文本的情况,避免在计算相似度时出现异常。
import unittest
from main import calculate_similarityclass TestSimilarityCalculation(unittest.TestCase):def test_calculate_similarity_empty(self):"""测试空文本的相似度计算错误场景:两篇文本均为空"""similarity = calculate_similarity("", "")self.assertEqual(similarity, 0.0)def test_calculate_similarity_mixed_empty(self):"""测试一个空文本和一个正常文本的相似度计算错误场景:其中一篇文本为空"""similarity = calculate_similarity("这是正常文本内容。", "")self.assertEqual(similarity, 0.0)
3.命令行参数异常
设计目标: 提供清晰的使用说明,引导用户正确使用程序。
对应场景:处理命令行参数数量不正确的情况,当用户提供的参数数量不符合要求时。
import unittest
import subprocess
import sys
from main import mainclass TestCommandLineArguments(unittest.TestCase):def test_main_wrong_arguments(self):"""测试命令行参数错误的情况错误场景:用户提供的命令行参数数量不足"""cmd = [sys.executable, 'main.py', 'only_one_argument.txt']result = subprocess.run(cmd, capture_output=True, text=True)self.assertNotEqual(result.returncode, 0)error_output = result.stderr + result.stdoutself.assertIn("使用方法", error_output)