上效果:
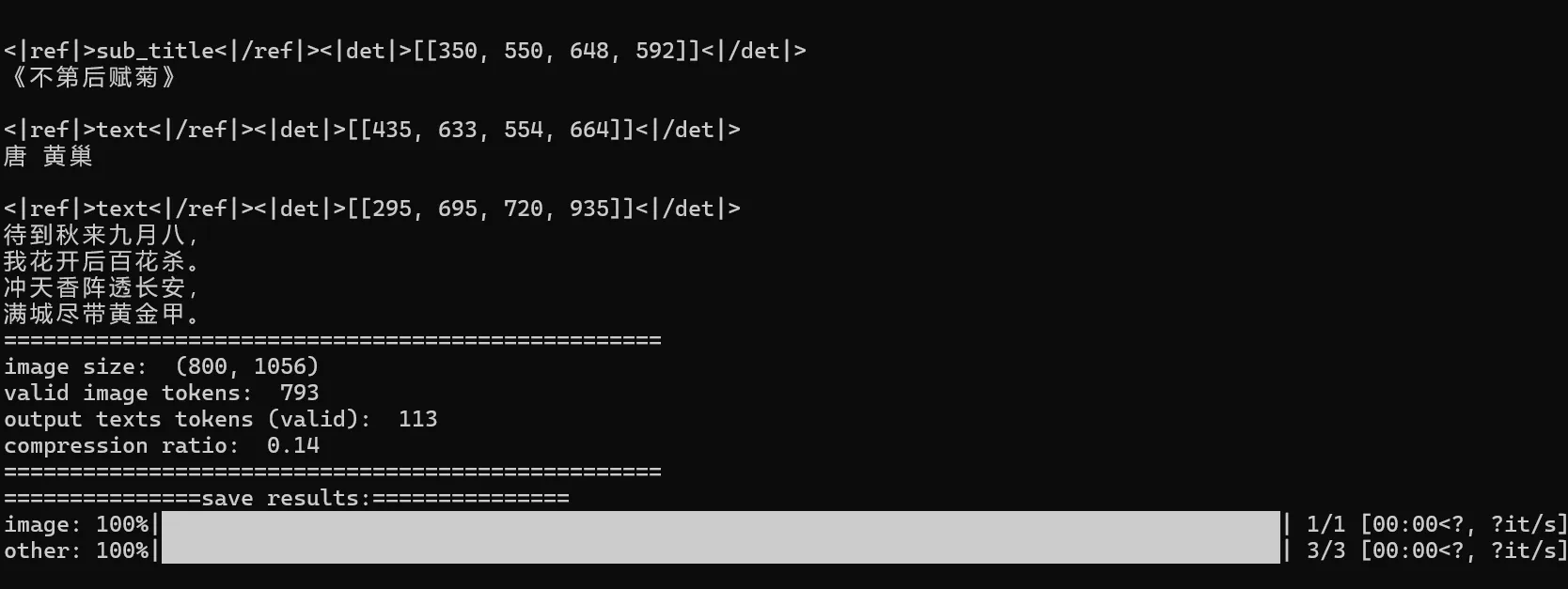

结论:windows官方示例仅可转换图片,linux下官方示例可转图片和PDF文件。
原因是转换PDF的代码用到了vllm,vllm仅可在linux系统下部署使用。(仅官方示例,如果自己编写代码进行PDF转图片,并处理多张图片的上下文语义,那么就没差别了)
deepseek-ocr 官方库提供了 transformers和vllm两种推理解析方式,transformers仅提供了图片识别的示例,vllm提供了图片识别和pdf识别两种示例。vllm仅可在linux系统下部署使用。
如果只需要图片识别,windows和linux两种系统都可以。如果需要pdf识别,则需要使用linux系统部署。
我的电脑环境:
windows 11、显卡 5060
deepseek-ocr官方代码库:https://github.com/deepseek-ai/DeepSeek-OCR
需要安装的内容:
git、python、Anaconda、cuda、pytorch(torch、torchvision、torchaudio、numpy)
我电脑使用的版本如下
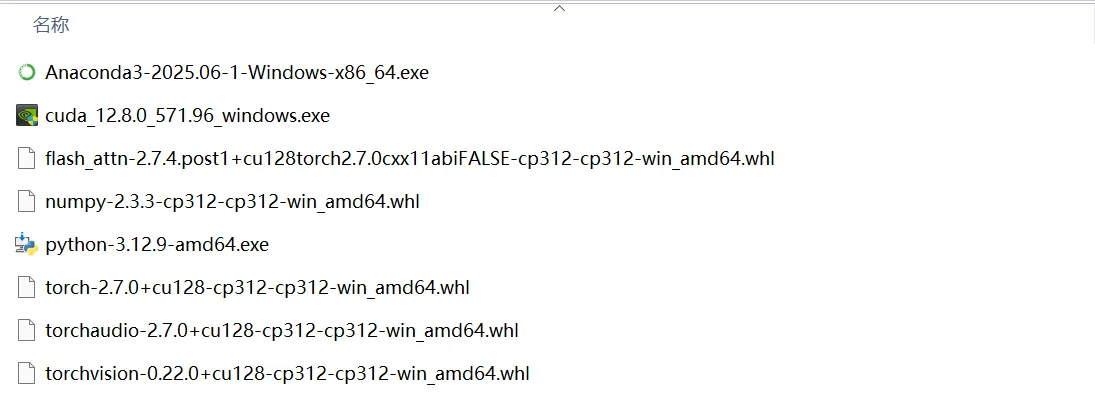
环境安装中因为CUDA版本不匹配,模型识别不了,反复切换过几次cuda、troch、flash_attn的版本。
这些软件的版本需要根据个人电脑显卡型号确定,一定要根据自己的电脑配置情况下载匹配版本,下边会详细介绍。
安装部署过程
1、安装git:
为了拉取deepseek-ocr的项目代码(如果电脑已经安装跳过,安装系统可以使用的版本即可)
https://git-scm.com/install/windows
从官网下载对应电脑程序,一步步安装即可。
2.获取deepseek-ocr 代码仓库
从电脑上想安装deepseek-ocr的文件夹下输入cmd

在打开的命令窗口中,输入 git clone https://github.com/deepseek-ai/DeepSeek-OCR.git
3.安装python 3.12.9
deepseek-ocr 推荐的python版本是3.12.9,建议安装此版本
https://www.python.org/downloads/windows/
下载自己电脑适合的版本
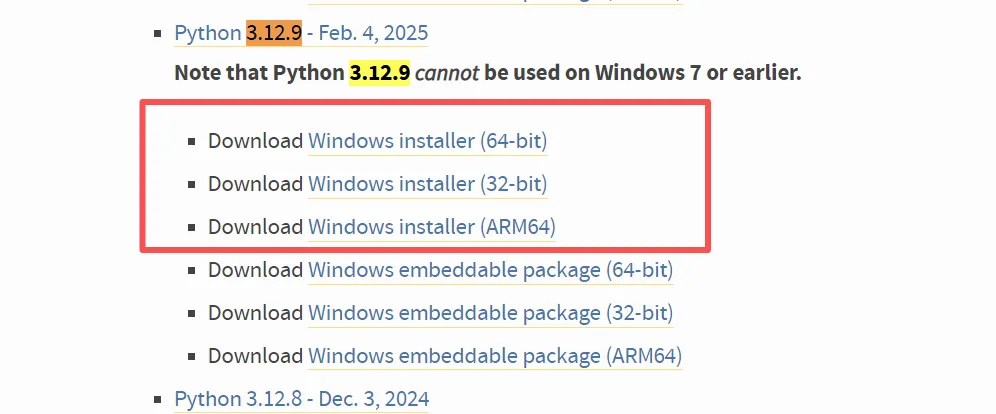
注意:下边两个复选框要勾上再点 安装或 install ,之后一步步安装即可。

不会安装的可以 参考:https://blog.csdn.net/biancheng_syz/article/details/139995035
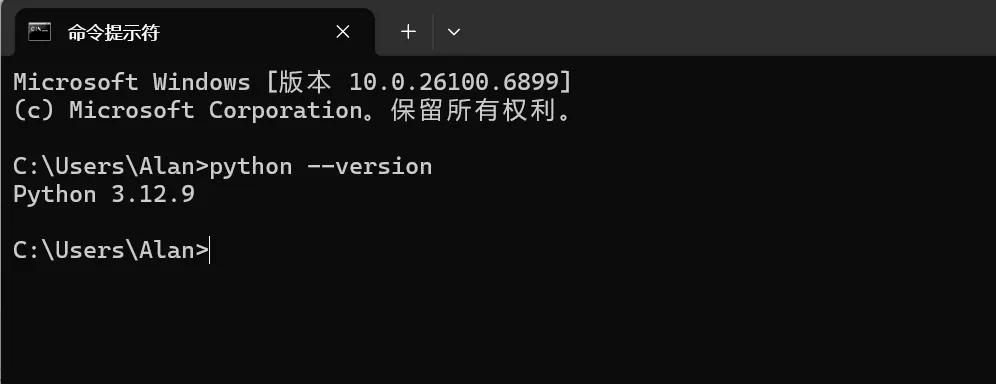
安装完成后在命令框中 输入 python --version,返回如下结果即可。
4.安装 Anaconda
可以从官网或镜像网站中下载
官网:https://www.anaconda.com/download
镜像地址:https://repo.anaconda.com/archive/
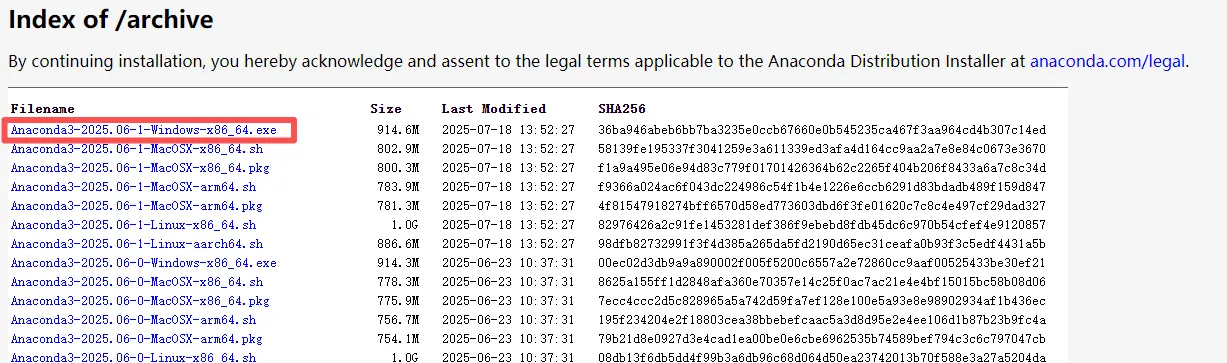
一步步安装即可,此处记得勾选下
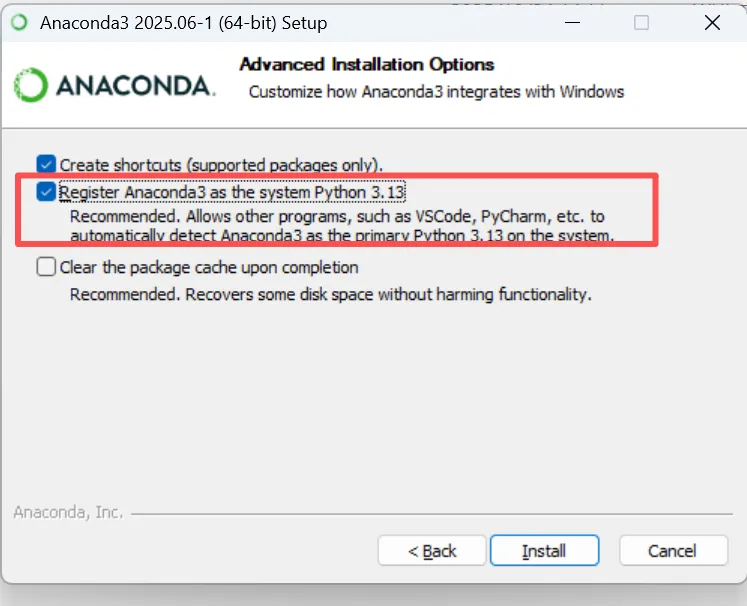
安装完成后在环境变量中增加配置
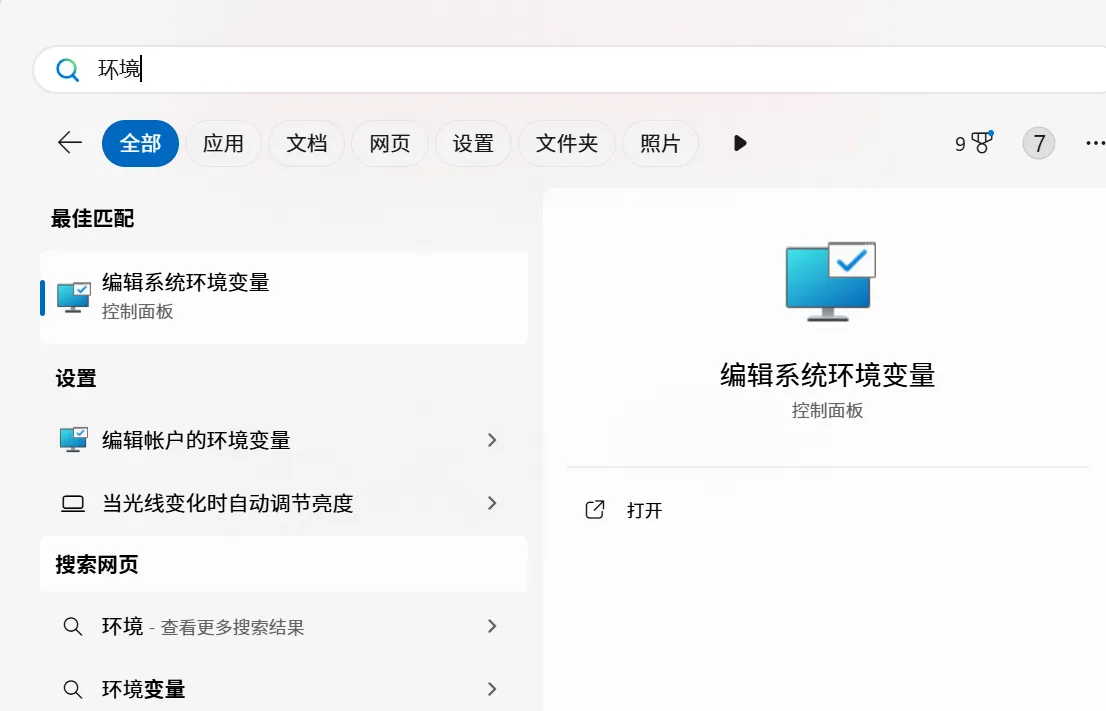
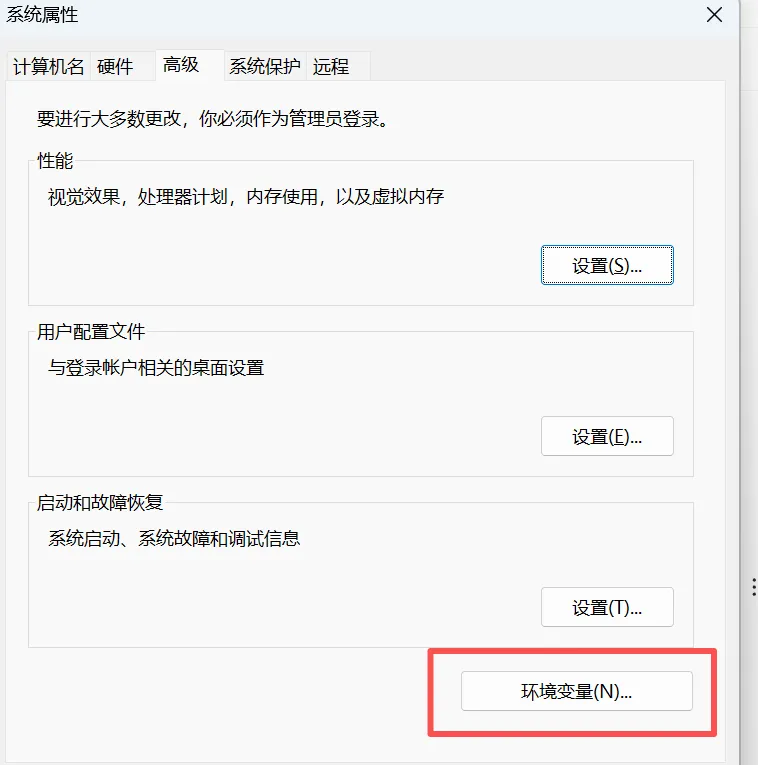
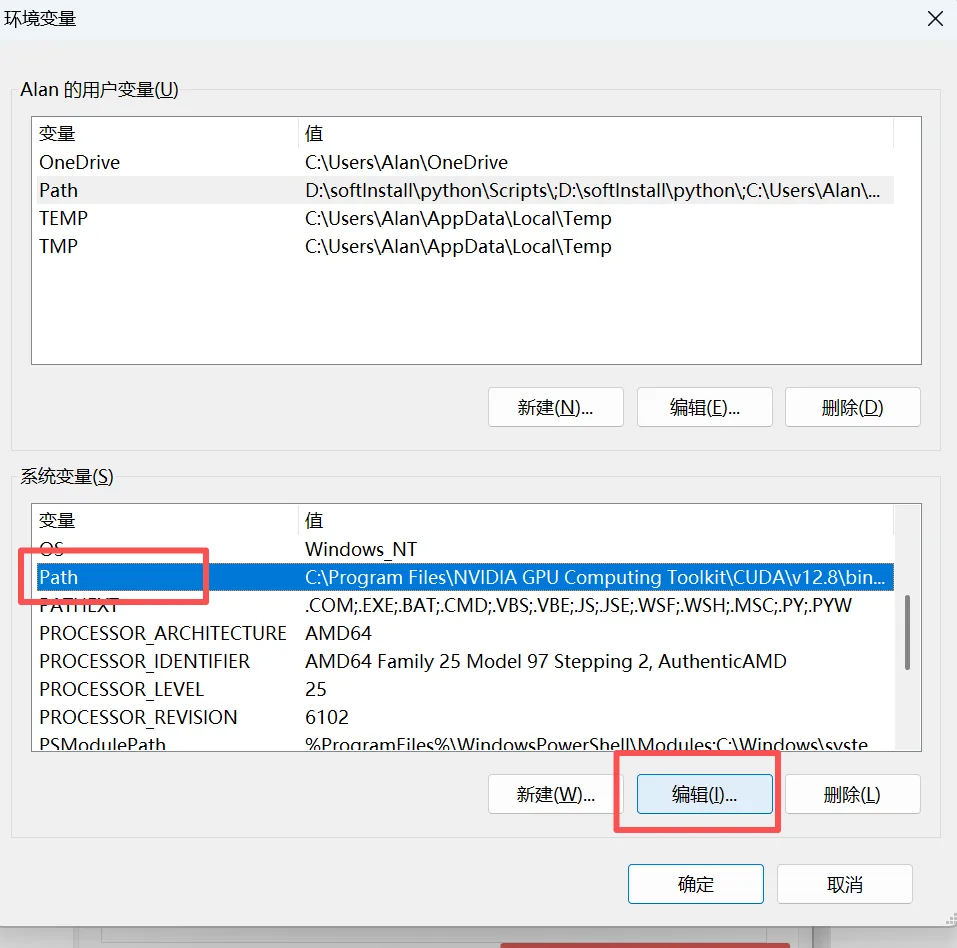
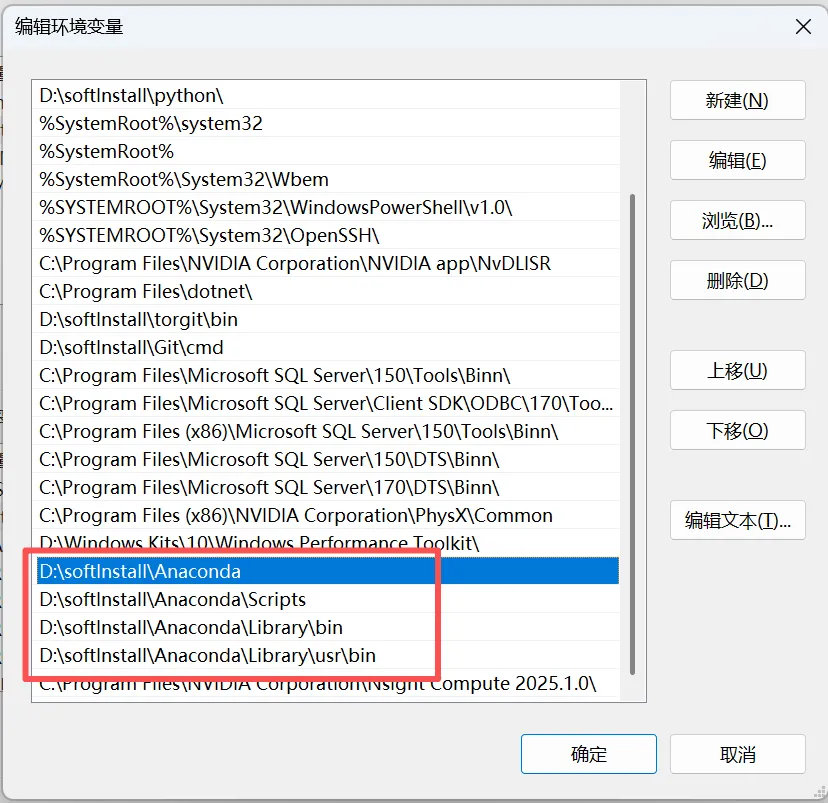
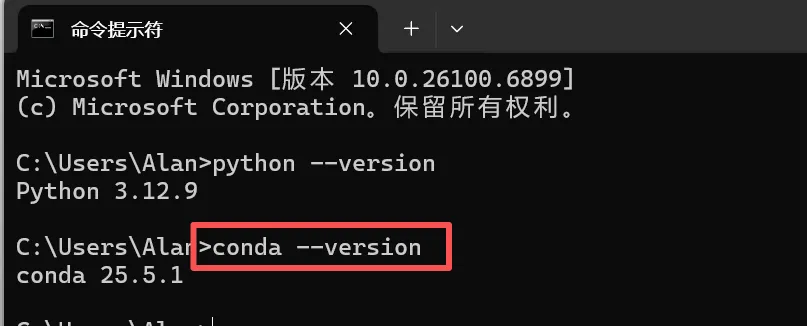
增加以上4项内容,D:\softInstall\Anaconda是我的安装目录,需要换成你自己的安装目录,配置完成后cmd 输入conda --version,返回如下信息即安装成功
5.安装CUDA (一定要注意版本、一定要注意版本)
deepseek推荐使用11.8,不用必须11.8,之上即可。
![]()
安装之前 cmd 进入命令行,检查驱动和cuda支持版本
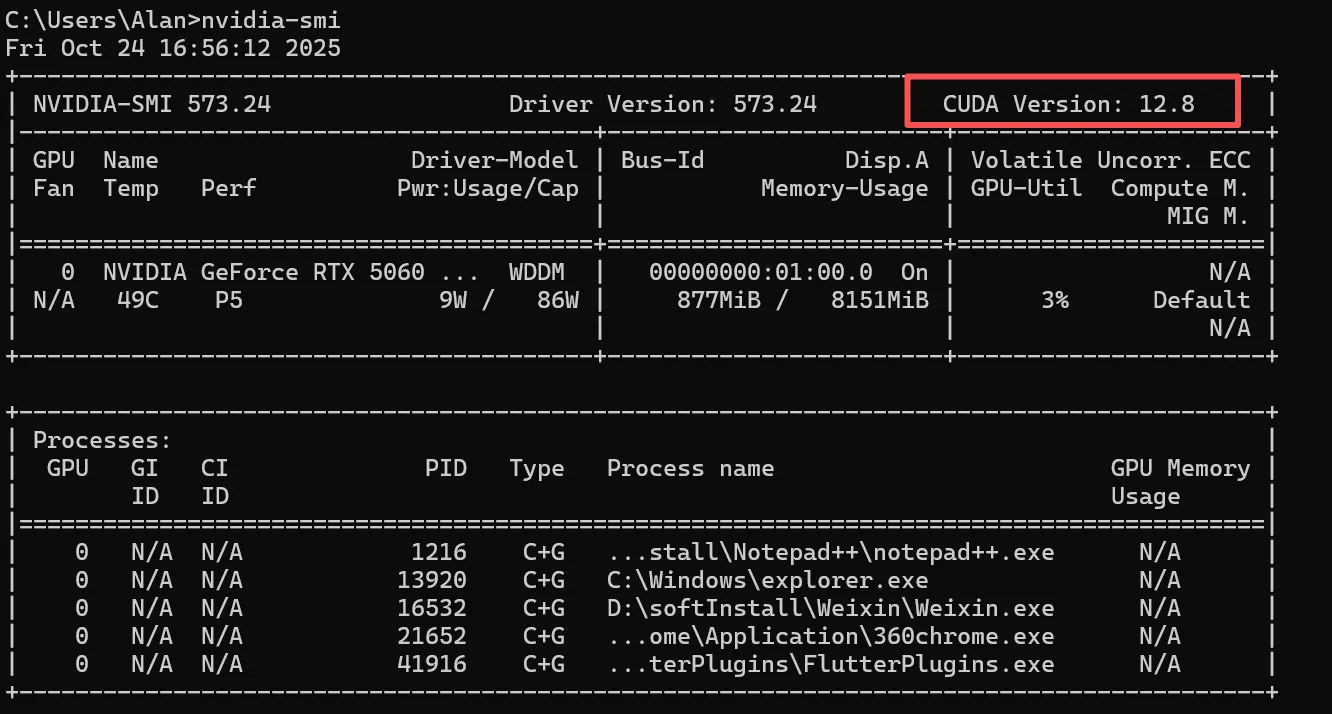
我的是12.8,进入cuda官网下载https://developer.nvidia.com/cuda-toolkit-archive
根据自己电脑型号选好
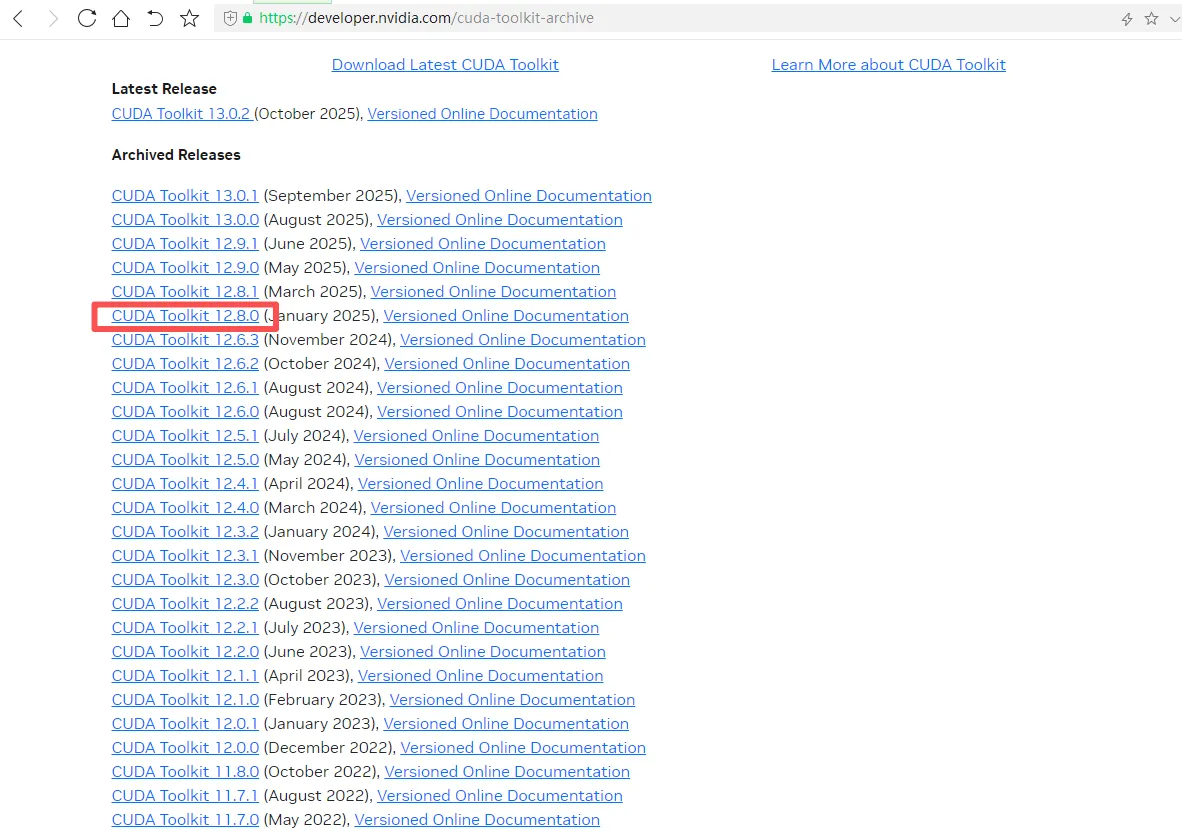
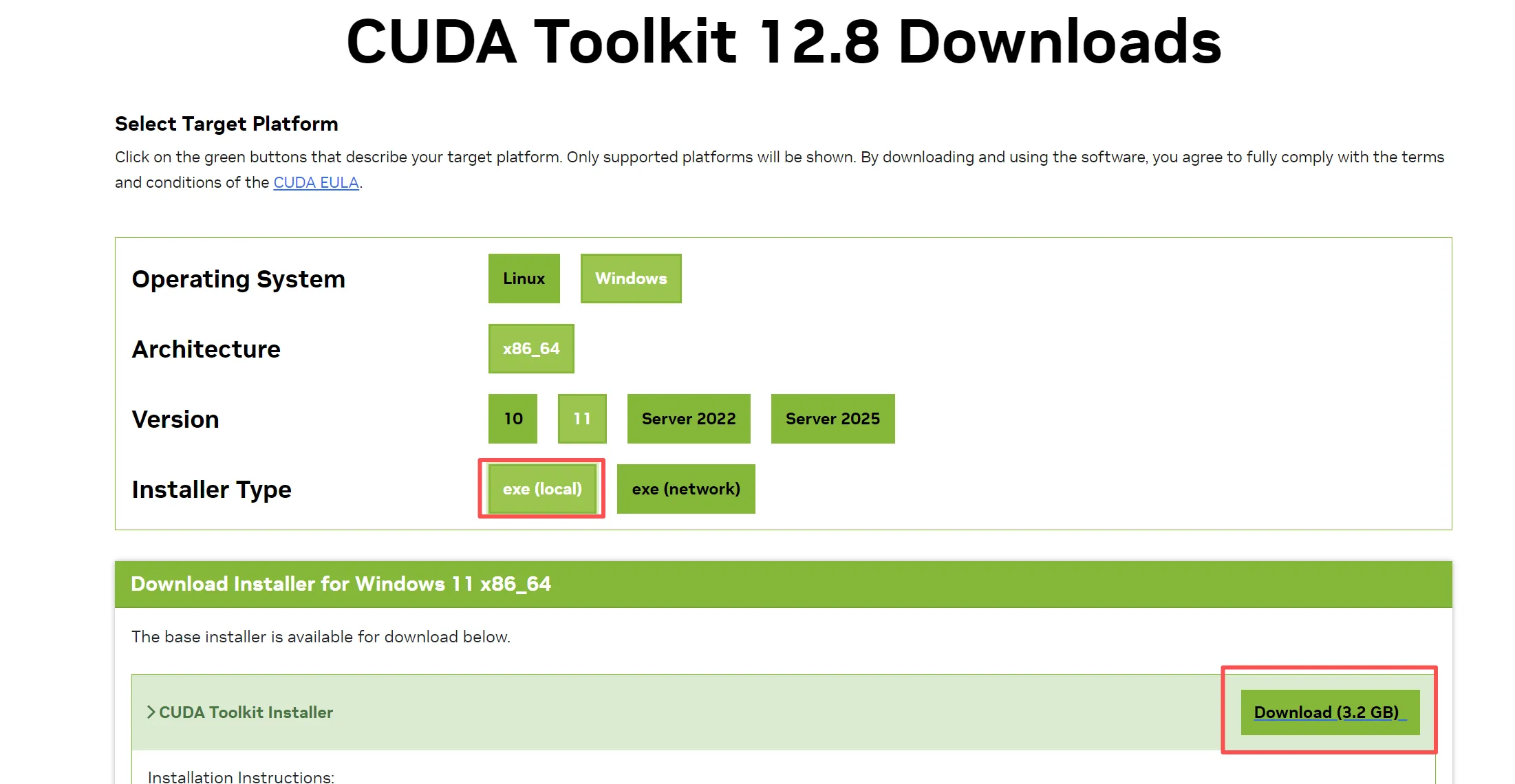
选择对应版本下载后,一路下一步安装即可,安装完成后,cmd, 输入 nvcc -V,返回版本信息即可
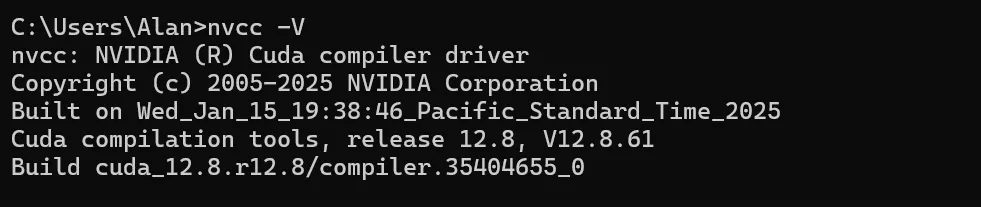
6.安装PyTorch(一定要注意版本、一定要注意版本)
deepseek-ocr自己环境使用的 2.6.0,我这使用的 2.7.0,因为适配cuda12.8版本的最低的 pytorch就是2.7.0
pytorch版本需要需要根据前边安装的cuda和python的版本进行安装,匹配规则解释:
cu128 代表 cuda版本是12.8,cp312 代表 python版本 3.12.X win就是windows;

pytorch 可以使用命令下载安装,也可以下载文件后本地安装,我使用的下载后本地安装
下载地址
https://download.pytorch.org/whl/nightly/cu128 其中128为显卡版本号
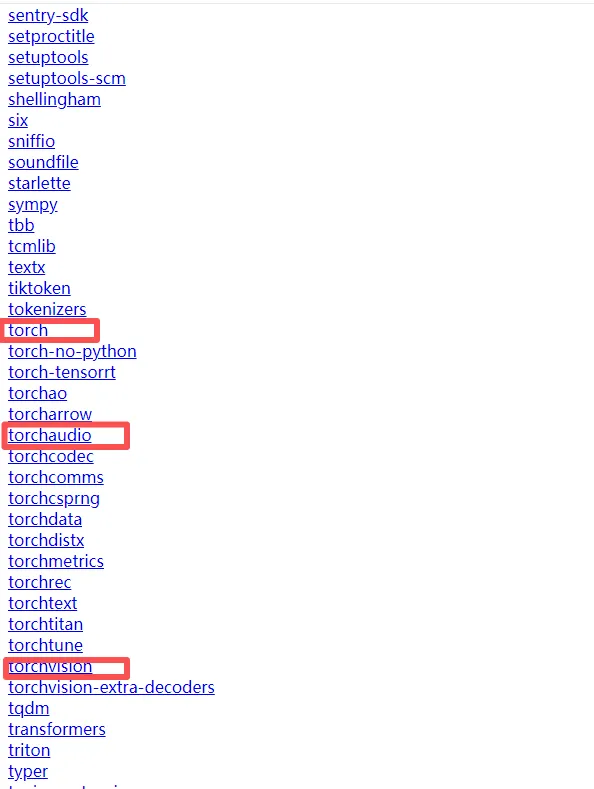
进入对应文件目录,按照上边说的匹配规则查找对应文件下载到本机。
进入下载完成的文件夹目录,在目录中输入cmd,
打开命令行后依次输入命令安装,install 后为下载的文件名 注意改成自己的
pip install torch-2.7.0+cu128-cp312-cp312-win_amd64.whl
pip install torchaudio-2.7.0+cu128-cp312-cp312-win_amd64.whl
pip install torchvision-0.22.0+cu128-cp312-cp312-win_amd64.whl
pip install numpy-2.3.3-cp312-cp312-win_amd64.whl
7.创建deepseek-ocr项目并激活
进入第一步拉取的deepseek-ocr项目目录下 输入cmd,打开命令窗口
conda create -n deepseek-ocr python=3.12.9 -y
conda activate deepseek-ocr
执行成功效果如下
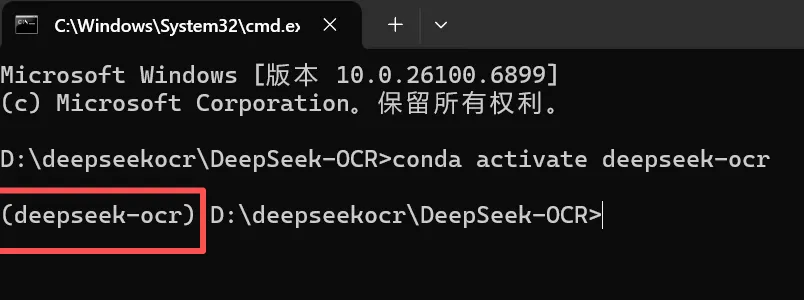
如果第一次执行activate,需要先执行下 conda init 后再执行 conda activate deepseek-ocr 即可。
8、安装依赖文件
继续在上边项目命令窗口中执行 pip install-r requirements.txt ,安装项目依赖的一些文件
9.安装flash-attn
此文件也要注意版本,很多人安装不上就是卡在这一步了。
问题1:在线安装成功率低
在线安装可以使用类似命令:pip install flash-attn==2.7.4 --no-build-isolation
我采用的方式是下载到本地再安装。
官网推荐使用的2.7.3跟我的cuda12.8,PyTorch 2.7.0不匹配,所以按照规则,去下载使用自己的版本
此处window环境下编译的版本不好找,废了半天劲找到了这个宝藏地址,注意cu、torch、cp版本号,分别需要与cuda、PyTorch、python的版本保持一致
https://github.com/kingbri1/flash-attention/releases
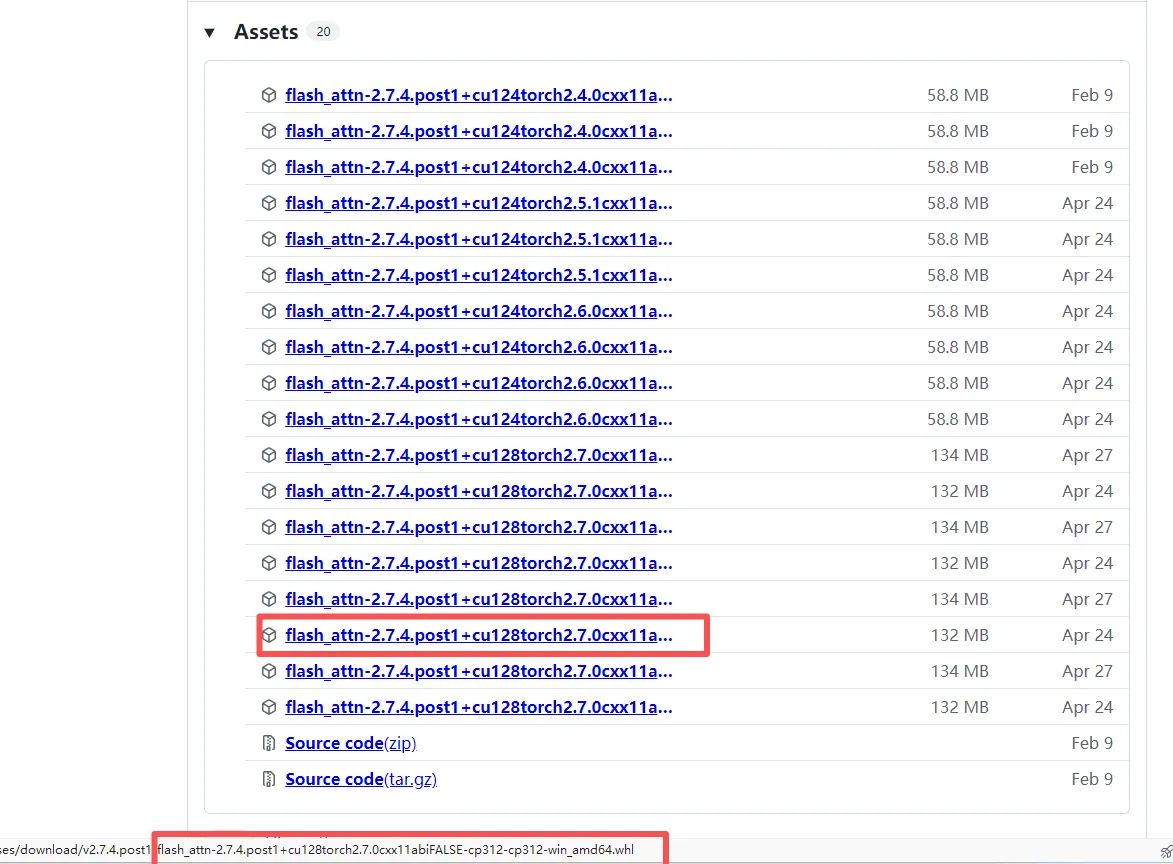
问题2:文件下载到本地时 名称中的+号会丢失变为空白 需修改下文件名补充上
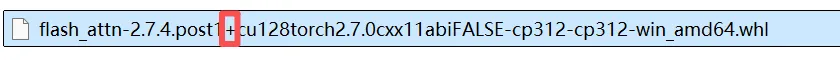
下载完成后,在对应目录cmd打开命令窗口安装flash_attn,执行
pip install flash_attn-2.7.4.post1+cu128torch2.7.0cxx11abiFALSE-cp312-cp312-win_amd64.whl
提示success 的一段提示即代表安装成功
10.下载模型文件到本地
ModelScope下载地址:https://modelscope.cn/models/deepseek-ai/DeepSeek-OCR/summary
按照提示下载模型到本地即可

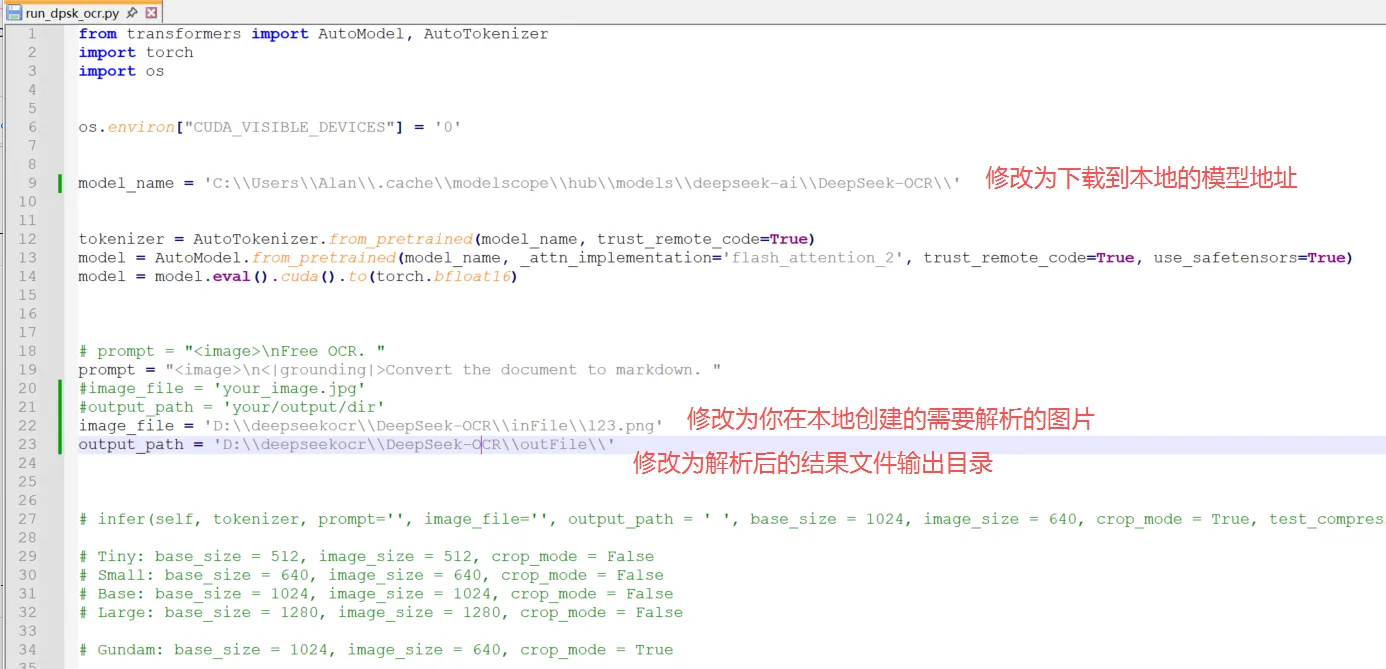
11、更改deepseek-ocr中模型文件目录,和要解析的输入输出文件目录
这就是开头提到的windows局限的地方,
linux下边 可以在安装上vllm模型,按照这种方式 对pdf进行识别解析。
https://github.com/vllm-project/vllm/releases/tag/v0.8.5
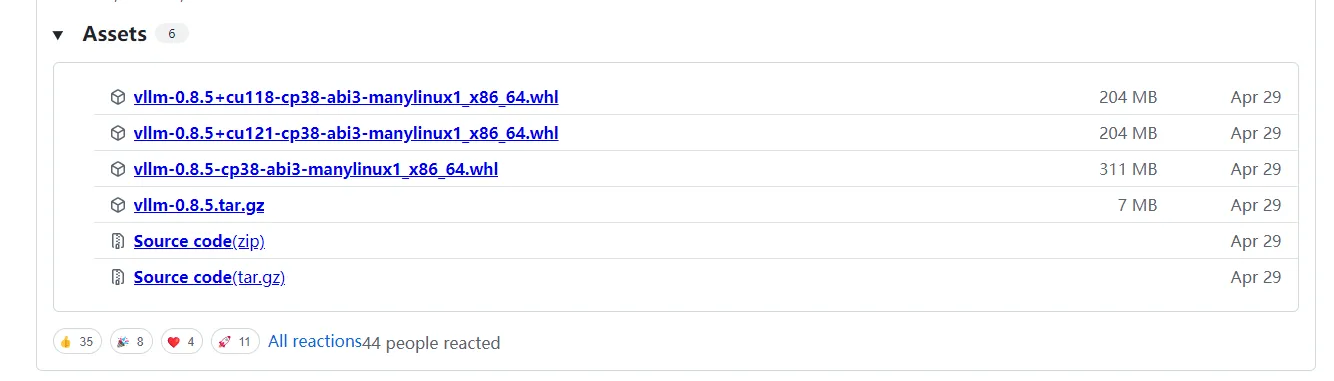
windows下暂不支持,如多直接使用官方示例在DeepSeek-OCR-hf下仅可对图片进行识别,未提供直接可用的PDF识别示意代码。可以自己写代码处理PDF转换(后续上示例)。

12.上才艺

输入目录种的文档:

一个解析识别后的图片示意、一个markdown的文件,一个图片文件夹
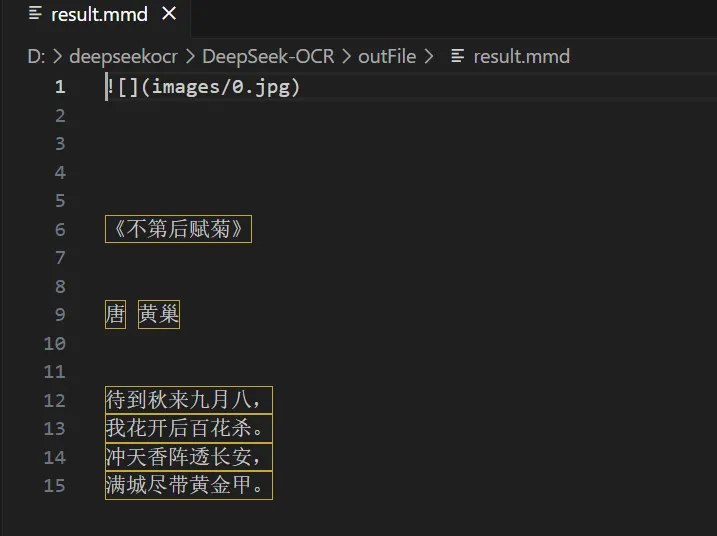
效果还是挺好的,识别速度、准确率都不错。后边做分析和项目实战再做分享。