获取更多高质量数据集,请访问典枢数据交易平台:https://dianshudata.com/
引言与背景
在数字化转型的浪潮中,票据识别技术已成为金融、零售、餐饮等行业自动化处理的核心技术。传统的票据处理依赖人工录入,效率低下且容易出错,而基于深度学习的票据识别系统能够实现高精度的自动化信息提取。然而,训练高质量的票据识别模型需要大量标注良好的数据集作为支撑。
本数据集专门为票据识别和文档理解研究而设计,包含了丰富的收据图像样本和详细的结构化标注信息。该数据集不仅为研究人员提供了标准化的训练和测试基准,更为产业界开发实用的票据处理系统奠定了坚实的数据基础。通过使用本数据集,研究人员可以训练端到端的文档理解模型,实现从图像到结构化数据的直接转换,推动票据识别技术向更高精度和更强泛化能力的方向发展。
数据基本信息
本数据集包含总计1000个高质量的收据图像样本,其中训练集800个样本,验证集100个样本,测试集100个样本。每个样本包含一张清晰的收据扫描图像和对应的JSON格式结构化标注信息。
图像数据采用PNG格式存储,平均分辨率为999×1575像素,图像尺寸范围从204×336到3024×4224,确保了数据的多样性和真实性。标注信息涵盖了收据中的所有关键信息,包括商品名称、数量、价格、小计、税费、总计等结构化数据。
数据集共包含2141个商品项标注,涵盖1504种不同的商品类型,价格范围从0到18,150,000,平均价格为172,238。这种丰富的价格分布和商品多样性使得数据集能够支持各种复杂场景下的模型训练和评估。
数据优势
|
特征维度 |
具体描述 |
优势与价值 |
|---|---|---|
|
图像质量 |
所有收据图像均为高分辨率扫描图像,图像清晰度高,文字识别难度适中。 |
为模型训练提供了优质的视觉输入,减少了因图像模糊、失真导致的识别错误,奠定了高准确率的基石。 |
|
标注完整性 |
每个样本都包含详细的JSON格式标注,不仅提供文本内容,还包含精确的边界框坐标(通常为多边形或四边形)。 |
支持端到端的OCR模型训练(如DBNet、PaddleOCR),并允许进行细粒度的文本分析和布局理解,远超仅提供文本内容的数据集。 |
|
数据多样性 |
涵盖多种收据类型和格式(如零售、餐饮、交通等),包含不同语言、不同排版布局的收据样本。 |
极大地提高了训练模型的泛化能力,使其能够更好地适应真实世界中遇到的各种未知收据格式,避免过拟合。 |
|
格式标准化 |
采用统一的数据分割(如train/val/test)和标注格式(如COCO、ICDAR等通用格式)。 |
便于研究人员和开发者快速上手使用,无需复杂的格式转换,可直接与主流深度学习框架(PyTorch, TensorFlow, MMOCR)兼容。 |
|
文本定位精度 |
提供每个文本元素(单词或文本行)的精确坐标信息,而非整图或整行级别的粗粒度标注。 |
完美支持需要基于位置的信息提取(Key-Information Extraction, KIE)和文档布局分析(Document Layout Analysis, DLA)任务。 |
| 获取方式 |
数据样例


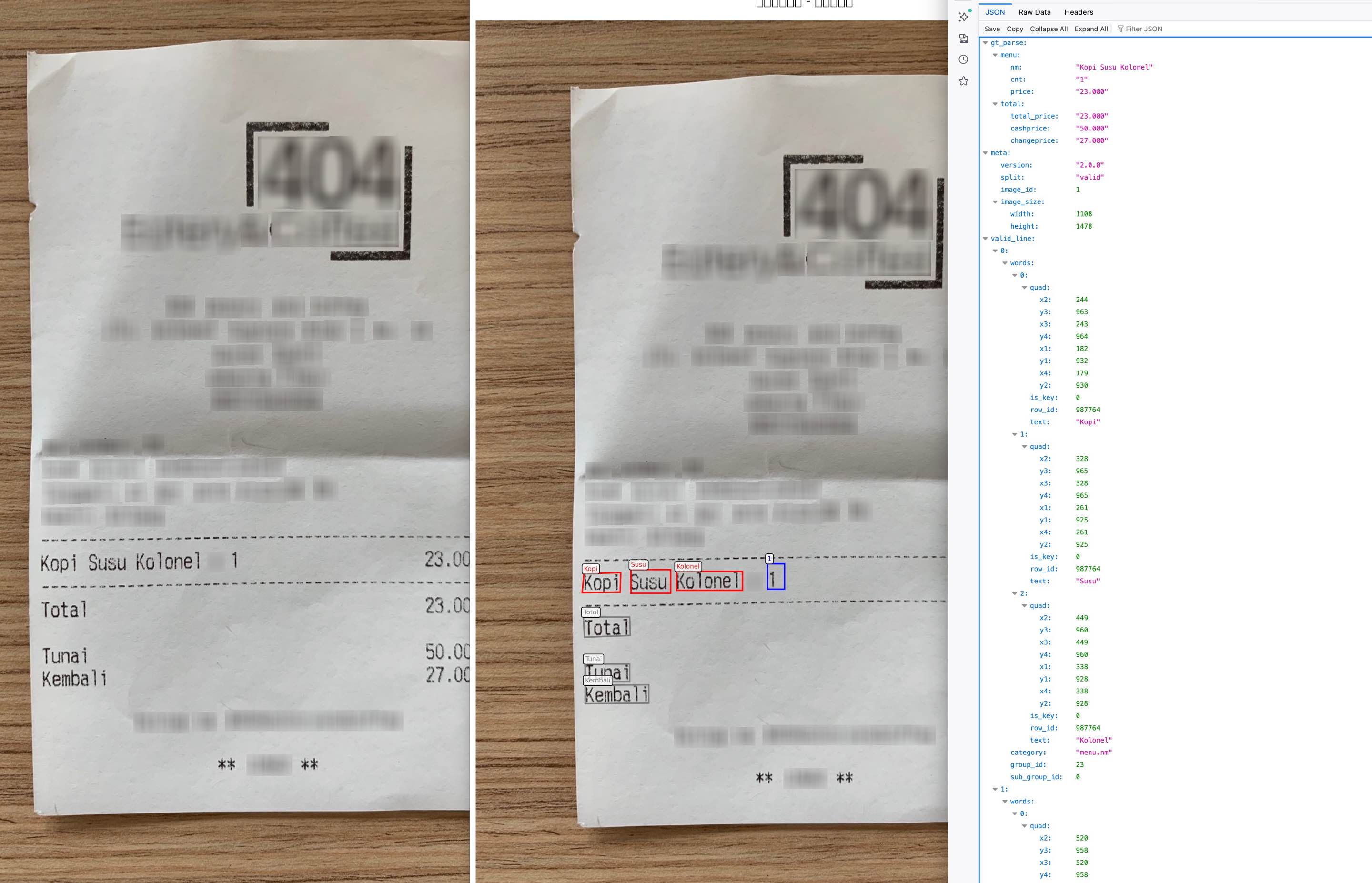
应用场景
端到端票据OCR系统开发
本数据集为开发端到端的票据OCR系统提供了理想的数据基础。传统的OCR系统通常需要先进行文本检测,再进行文本识别,最后进行信息结构化,这种多步骤的处理方式容易产生误差累积。而基于本数据集训练的端到端模型可以直接从收据图像输出结构化的JSON数据,大大简化了处理流程。
在实际应用中,这种端到端的票据OCR系统可以广泛应用于餐饮、零售、酒店等行业的收银系统。系统能够自动识别收据中的商品信息、价格、税费等关键数据,实现收据信息的自动录入和核对。这不仅提高了工作效率,还减少了人工错误,为企业节省了大量的人力成本。同时,系统还可以与财务管理系统、库存管理系统等企业应用无缝集成,实现业务流程的全面自动化。
智能财务管理系统构建
在财务管理领域,本数据集为构建智能财务管理系统提供了重要的数据支撑。传统的财务数据录入需要人工逐条输入收据信息,工作量大且容易出错。基于本数据集训练的模型可以实现收据信息的自动提取和分类,大大提高财务处理的效率和准确性。
智能财务管理系统可以自动识别收据中的供应商信息、商品明细、金额数据等关键信息,并按照预设的规则进行分类和归档。系统还能够自动计算税费、生成财务报表,为企业的财务决策提供及时准确的数据支持。此外,系统还具备异常检测功能,能够识别异常的金额、重复的收据等问题,帮助企业及时发现和防范财务风险。这种智能化的财务管理方式不仅提高了工作效率,还增强了财务数据的准确性和可靠性。
零售数据分析与推荐系统
本数据集为零售行业的数据分析和推荐系统开发提供了宝贵的数据资源。通过分析收据中的商品购买信息,可以深入了解消费者的购买行为和偏好,为精准营销和个性化推荐提供数据基础。
基于收据数据的分析可以揭示商品之间的关联关系,发现消费者的购买模式,为商品陈列、促销策略制定提供科学依据。例如,通过分析哪些商品经常一起购买,可以优化商品陈列位置,提高交叉销售的效果。同时,系统还可以根据消费者的历史购买记录,推荐可能感兴趣的商品,提高销售转化率。
此外,收据数据还可以用于库存管理优化,通过分析商品的销售频率和数量,可以预测未来的需求趋势,优化采购计划和库存配置,减少库存积压和缺货风险。
文档理解与布局分析研究
本数据集为文档理解和布局分析研究提供了标准化的测试基准。收据作为一种典型的半结构化文档,具有明确的布局特征和语义结构,是研究文档理解技术的理想对象。
研究人员可以利用本数据集开发新的文档理解算法,探索如何更好地理解文档的布局结构和语义关系。例如,可以研究如何利用视觉特征和文本特征相结合的方式,提高信息提取的准确性。还可以探索基于注意力机制的模型架构,让模型能够更好地关注文档中的关键信息区域。
这些研究成果不仅适用于收据识别,还可以推广到发票、合同、报告等其他类型的文档处理任务中。通过在本数据集上的验证和改进,研究人员可以开发出更加通用和强大的文档理解技术,推动整个文档智能处理领域的发展。
结尾
本票据识别数据集以其高质量的数据内容、完整的标注信息和丰富的应用场景,为票据识别和文档理解研究提供了重要的数据支撑。数据集不仅能够支持传统的OCR技术研究,更能够推动端到端文档理解技术的发展,为产业界的智能化转型提供技术基础。
通过使用本数据集,研究人员可以开发出更加准确、高效的票据识别系统,为金融、零售、餐饮等行业提供智能化的数据处理解决方案。同时,数据集也为文档理解、布局分析等前沿研究领域提供了标准化的测试基准,推动相关技术的持续创新和发展。
有需要可私信获取更多信息,我们将为您提供详细的数据集使用指南和技术支持。